
Population Genomics of Sub-Saharan : African Diversity and Non-African Admixture
Drosophila melanogaster has played a pivotal role in the development of modern population genetics. However, many basic questions regarding the demographic and adaptive history of this species remain unresolved. We report the genome sequencing of 139 wild-derived strains of D. melanogaster, representing 22 population samples from the sub-Saharan ancestral range of this species, along with one European population. Most genomes were sequenced above 25X depth from haploid embryos. Results indicated a pervasive influence of non-African admixture in many African populations, motivating the development and application of a novel admixture detection method. Admixture proportions varied among populations, with greater admixture in urban locations. Admixture levels also varied across the genome, with localized peaks and valleys suggestive of a non-neutral introgression process. Genomes from the same location differed starkly in ancestry, suggesting that isolation mechanisms may exist within African populations. After removing putatively admixed genomic segments, the greatest genetic diversity was observed in southern Africa (e.g. Zambia), while diversity in other populations was largely consistent with a geographic expansion from this potentially ancestral region. The European population showed different levels of diversity reduction on each chromosome arm, and some African populations displayed chromosome arm-specific diversity reductions. Inversions in the European sample were associated with strong elevations in diversity across chromosome arms. Genomic scans were conducted to identify loci that may represent targets of positive selection within an African population, between African populations, and between European and African populations. A disproportionate number of candidate selective sweep regions were located near genes with varied roles in gene regulation. Outliers for Europe-Africa FST were found to be enriched in genomic regions of locally elevated cosmopolitan admixture, possibly reflecting a role for some of these loci in driving the introgression of non-African alleles into African populations.
Published in the journal:
. PLoS Genet 8(12): e32767. doi:10.1371/journal.pgen.1003080
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1003080
Summary
Drosophila melanogaster has played a pivotal role in the development of modern population genetics. However, many basic questions regarding the demographic and adaptive history of this species remain unresolved. We report the genome sequencing of 139 wild-derived strains of D. melanogaster, representing 22 population samples from the sub-Saharan ancestral range of this species, along with one European population. Most genomes were sequenced above 25X depth from haploid embryos. Results indicated a pervasive influence of non-African admixture in many African populations, motivating the development and application of a novel admixture detection method. Admixture proportions varied among populations, with greater admixture in urban locations. Admixture levels also varied across the genome, with localized peaks and valleys suggestive of a non-neutral introgression process. Genomes from the same location differed starkly in ancestry, suggesting that isolation mechanisms may exist within African populations. After removing putatively admixed genomic segments, the greatest genetic diversity was observed in southern Africa (e.g. Zambia), while diversity in other populations was largely consistent with a geographic expansion from this potentially ancestral region. The European population showed different levels of diversity reduction on each chromosome arm, and some African populations displayed chromosome arm-specific diversity reductions. Inversions in the European sample were associated with strong elevations in diversity across chromosome arms. Genomic scans were conducted to identify loci that may represent targets of positive selection within an African population, between African populations, and between European and African populations. A disproportionate number of candidate selective sweep regions were located near genes with varied roles in gene regulation. Outliers for Europe-Africa FST were found to be enriched in genomic regions of locally elevated cosmopolitan admixture, possibly reflecting a role for some of these loci in driving the introgression of non-African alleles into African populations.
Introduction
Drosophila melanogaster has a well known history and ongoing role as a model organism in classical and molecular genetics. Its well-annotated genome [1], [2] and genetic toolkit have also made it an important model organism in the field of population genetics, in many cases motivating the development of broadly applicable theoretical models and statistical methods. Prior to the advent of DNA sequencing, studies of inversions and allozymes in D. pseudoobscura [3], [4], and later D. melanogaster [5], [6], provided some of the field's first glimpses of genetic polymorphisms within and between populations, often providing evidence for geographic clines consistent with local adaptation.
The analysis of DNA sequence data from the Drosophila Adh gene motivated the development of methods that compare polymorphism and divergence at different gene regions [7] or functional categories of sites [8], and offered examples of non-neutral evolution. Sequence polymorphism data from additional D. melanogaster genes revealed that recombination rate is strongly correlated with nucleotide diversity but not between-species divergence in D. melanogaster [9]. This result suggested that genetic hitchhiking [10] could be an important force in molding diversity across the Drosophila genome, but it also motivated the suggestion that background selection against linked deleterious variants [11] should likewise reduce diversity in low recombination regions of the genome.
Larger multi-locus data sets initially came from studies of microsatellites and short sequenced loci. Several of these studies compared variation between ancestral range populations from sub-Saharan Africa and more recently founded temperate populations from Europe, finding that non-African variation is far more strongly reduced on the X chromosome than on the autosomes [12], [13]. Sequence data also allowed larger-scale comparisons of polymorphism and divergence, leading to suggestions that significant fractions of substitutions at nonsynonymous sites [14] and non-coding sites [15] were driven by positive selection.
Although previous studies have found considerable evidence for a genome-wide influence of natural selection, a thorough and confident identification of recent selective sweeps in the genome requires an appropriate neutral null model that incorporates population history. Both biogeography [16] and genetic variation [17], [18] indicate that D. melanogaster originated within sub-Saharan Africa. Even within Africa, D. melanogaster has only been collected from human-associated habitats, and so its original habitat and ecology, along with the details of its transition to a human commensal species, remain unknown [19]. A few studies have found populations from eastern and southern Africa to be the most genetically diverse [18], [20], [21], suggesting that the species' ancestral range may lie within these regions. Small but significant levels of genetic structure are present within sub-Saharan Africa [18], which could reflect either long-term restricted migration or short-term effects of bottlenecks associated with geographic expansions within Africa.
On the order of 10,000 years ago [22]–[24], D. melanogaster is thought to have first expanded beyond sub-Saharan Africa, perhaps by traversing formerly wetter parts of the Sahara [16] or the Nile Valley [18]. This expansion involved a significant loss of genetic variation [12], [13], brought D. melanogaster into the palearctic region (northern Africa, Asia, and Europe), and largely gave rise to the “cosmopolitan” populations that live outside sub-Saharan Africa today. American populations were founded only within the past few hundred years [25], and their complex demography appears to involve admixture between European and African source populations [26].
Recent advances in DNA sequencing technology have allowed genetic variation to be studied on the whole-genome scale. The sequencing of six D. simulans genomes [27] provided the first comprehensive look at fluctuations of polymorphism and divergence across the genome and their potential causes, including potential targets of adaptive evolution. More recently, larger samples of D. melanogaster genomes have been sequenced, yielding further insight into the potential impact of natural selection on diversity across the Drosophila genome [28], [29] and connections between genetic and phenotypic variation [29]. However, a large majority of the sequenced genomes are of North American origin, and before we can clearly understand the demographic history of that population, we must investigate genomic variation in its African and European antecedents.
Here, we use whole genome sequencing and population genomic analysis to examine genetic variation in wild-derived population samples of D. melanogaster. We use a new method to detect pervasive admixture from cosmopolitan into sub-Saharan populations. We use geographic patterns of genetic diversity and structure to investigate the history of D. melanogaster within Africa. Finally, we identify loci with unusual patterns of allele frequencies within or between populations, which may represent targets of recent directional selection.
Results
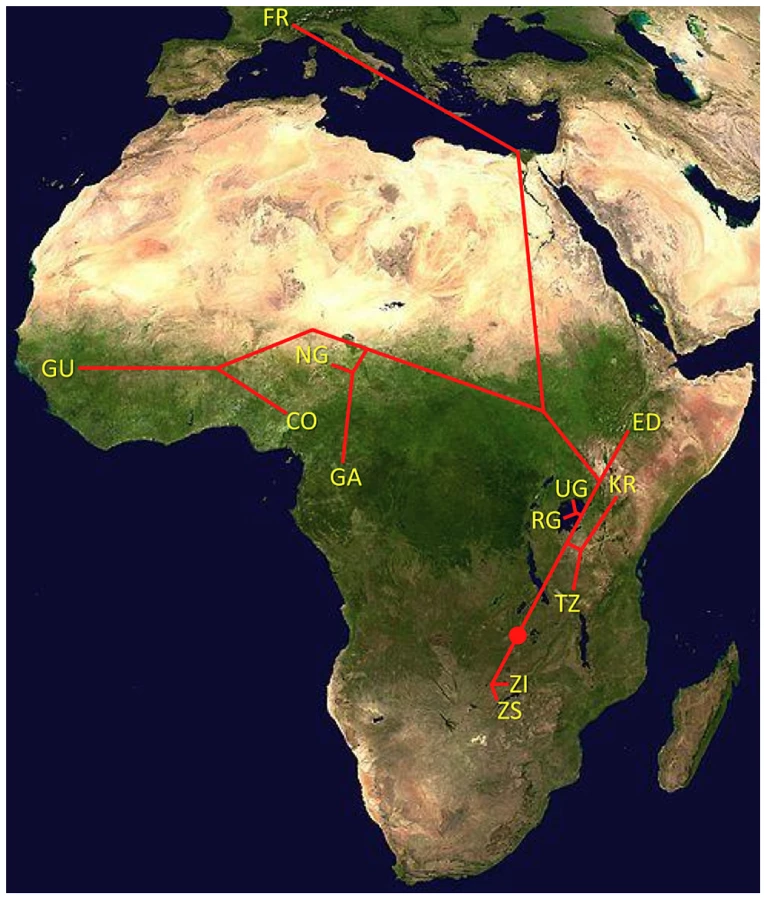
With the ultimate aim of identifying population samples of importance for future population genomic studies, we sequenced genomes from 139 wild-derived D. melanogaster fly stocks. These genomes represented 22 population samples from sub-Saharan Africa and one from Europe (Figure 1; Table S1; Table S2). Most of these genomes were obtained from haploid embryos [30]. These genomes were found to be essentially homozygous (with the exception of chromosome 2 from GA187 [28]). A smaller number of genomes were sequenced from homozygous chromosome extraction lines; those included in the published data were found to be homozygous for target chromosome arms (X, 2L, 2R, 3L, 3R). Three genomes (the ZK sample; Table S1) were sequenced from adult flies from inbred lines; these were found to have extensive residual heterozygosity (results not shown). The data we analyze below consists entirely of non-heterozygous sequences from haploid embryo genomes. Apparently heterozygous sites in target chromosome arms were observed at low rates in all genomes, potentially resulting from cryptic copy number variation or recurrent base-calling errors, and were excluded from analysis. Based on the rarity of such sites (approximately one per 20 kb on average), their exclusion seems unlikely to strongly influence genome-wide summary statistics.
Sequencing was performed using the Illumina Genome Analyzer IIx platform. Paired-end reads of at least 76 bp were sequenced for each genome (Table S2). Alignment was performed using BWA [31], with consensus sequences generated via SAMtools [32]. Reads with low mapping scores (<20) were discarded, and positions within 5 bp of a consensus indel were masked (treated as missing data) for the genome in question. Resequencing of the reference strain y1, cn1, bw1, sp1 and the addition of simulated genetic variation allowed the quality of assemblies to be assessed. Based on the inferred tradeoff between error rates and genome-wide coverage, a nominal BWA quality score of Q31 (corresponding to an estimated Phred score of Q48) was chosen as a quality threshold for subsequent analyses (Figure S1). Genomic regions with long blocks of identity-by-descent (IBD) consistent with relatedness were masked (Table S3; Table S4). A full description of data generation and initial analysis can be found in the Materials and Methods section. Processed and raw sequence data for all genomes can be found at http://www.dpgp.org/dpgp2/DPGP2.html and http://ncbi.nlm.nih.gov/sra.
Correlation of sequencing depth with genomic coverage and genetic distance
The sequenced genomes vary significantly in mean sequencing depth (average number of reads at a given bp) present in the assemblies. Among genomes with relevant data from all five target chromosome arms, mean depth ranges from 18X to 47X (Table S2). Depth was found to have a substantial influence on pairwise genetic distances. Mean depth showed positive, non-linear relationships with distance from the D. melanogaster reference genome, and with average distances to other African samples, such as Zambia-Siavonga (Figure 2A). The relationship between depth and genetic distance from Zambia is especially strong (Spearman ρ = 0.63; P<0.00001), suggesting that population ancestry has little influence on this quantity (a property of the ZI sample further discussed below). This correlation is especially pronounced for genomes with depth below 25X, while only a modest slope is present above this threshold.
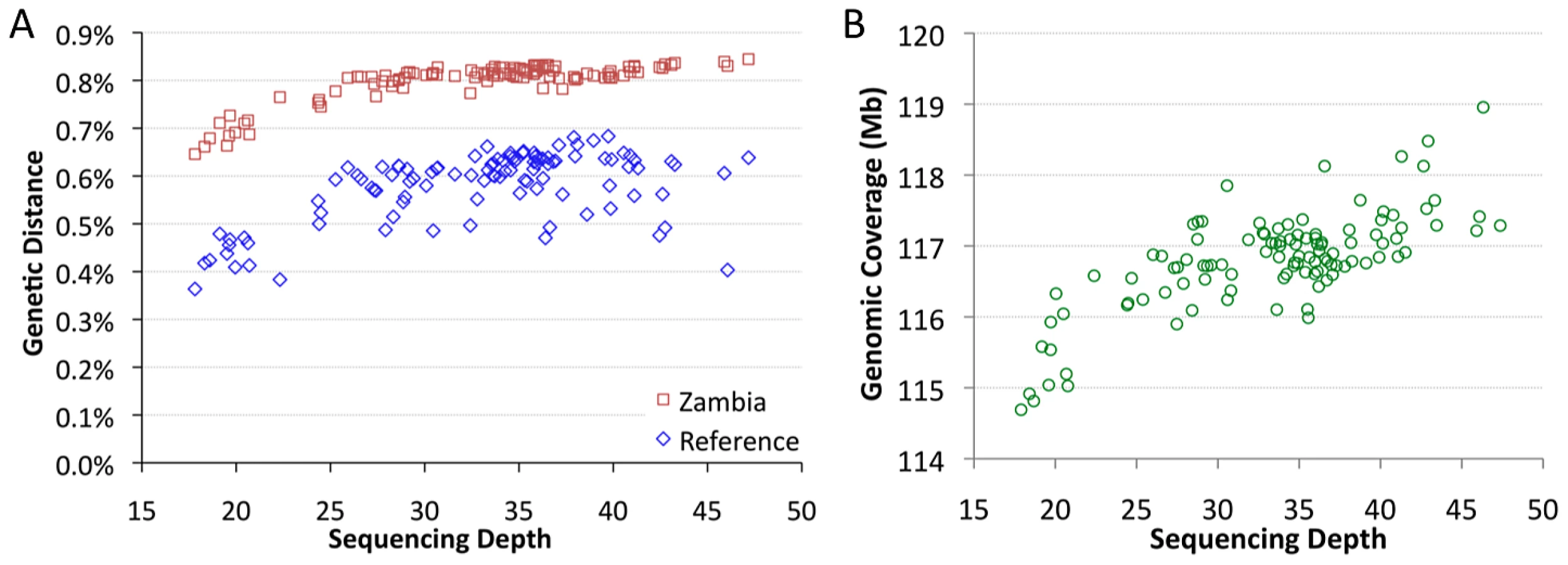
Mean depth was also correlated with genomic coverage – the portion of the genome with a called base at the quality threshold (Figure 2B; Spearman ρ = 0.62; P<0.00001). The lowest depth genomes were found to have ∼2% lower coverage than a typical genome with average depth. Some correlation of depth with genetic distance and genomic coverage might be expected if genomes with higher depth were more successful in mapping reads across genomic regions with high levels of substitutional (and perhaps structural) variation. Additionally, a consensus-calling bias in favor of the reference allele, such that higher depth genomes were more likely to have adequate statistical evidence favoring a non-reference allele, might contribute to the reduced genetic distances and genomic coverage exhibited by the lowest depth genomes.
The influence of depth on genetic distance has the potential to bias most population genetic analyses. We found that strict sample coverage thresholds (only analyzing sites covered in most or all assemblies) could ameliorate the depth-distance correlation, but at the cost of excluding most variation and introducing a substantial reference sequence bias (Figure S2). Instead, we addressed the depth-distance issue by focusing most analyses on genomes with >25X depth and made additional corrections when needed, as described below. Assemblies derived from haploid embryos with >25X depth were defined as the “primary core” data set (Table S1). Haploid embryo genomes with <25X depth were denoted as “secondary core”. Genomes not derived from haploid embryos were labeled “non-core”, and were not analyzed further in this study.
Identification of cosmopolitan admixture in sub-Saharan genomes
Previous work has suggested that introgression from cosmopolitan sources (i.e. populations outside sub-Saharan Africa) may be an important component of genetic variation for at least some African populations of D. melanogaster [18], [33], [34]. Preliminary examination of this data set revealed a number of sub-Saharan genomes with unusually low genetic distances to cosmopolitan genomes (the latter represented by the European FR sample and the North American reference genome). Undetected admixture could undermine the demographic assumptions of many population genetic methods, altering genetic diversity and population differentiation, and creating long-range linkage disequilibrium. Hence, we attempted to identify specific chromosome intervals that have non-African ancestry, so that they could be filtered from downstream analyses when appropriate.
We developed a Hidden Markov Model (HMM) method to identify chromosome segments from sub-Saharan genomes that have cosmopolitan ancestry, as described under Materials and Methods. The method utilized a “European panel” (the FR sample) and an “African panel” (the RG sample) which may contain some admixture. Because of the diversity-reducing out-of-Africa bottleneck, non-African genomes should be more closely related to each other than they are to African genomes. Therefore, if we examine genomic windows of sufficient length, genetic distances between two FR genomes should be consistently lower than between an RG and an FR genome (Figure S3). To take advantage of this contrast, we constructed chromosome arm-wide emissions distributions by evaluating two locally rescaled quantities in ∼50 kb windows. One distribution, representing African ancestry, was formed from genetic distances of each RG genome to the FR panel. The other distribution, representing non-African ancestry, was formed from genetic distances between each FR genome and the remainder of the FR panel. Individual African genomes were then compared to the FR panel to determine the likelihood of African or non-African ancestry in each window (essentially, using the emissions distributions to determine whether we are truly making an Africa-Europe genetic comparison, or if we are actually comparing two non-African alleles in the case of an admixed African genome). The HMM was then applied to convert likelihoods to admixture probabilities for each genome in each window. This approach was validated using simulations (see Materials and Methods; Figure S4). For the empirical data, the above approach was applied iteratively to the RG sample to eliminate non-African intervals from the “African panel” used to create emissions distributions. Emissions distributions generated using the FR and RG samples were also used to calculate admixture probabilities for the other sub-Saharan primary core genomes. Simple correction factors were applied to account for the effects of sequencing depth and other quality factors for each genome (Materials and Methods).
When applied to the RG primary core genomes, the admixture detection method produced generally sharp peaks along chromosome arms, with only 3.3% of window admixture probabilities between 0.05 and 0.95 (Figure S5; Table S5). When primary core genomes from other population samples were analyzed, results still appeared to be of reasonable quality, with 8.3% “intermediate” admixture probabilities as defined above (Figure S5; Table S5). However, inferences for the secondary core and non-core genomes appeared less reliable, with 22.5% intermediate admixture probabilities and more admixture predicted in general (Figure S5; Table S6). Hence, the influence of lower sequencing depth may have added significant “noise” into the admixture analysis. Below, we focus on admixture inferences from the primary core genomes only.
Inter-population variability in cosmopolitan admixture proportion
The estimated proportion of cosmopolitan admixture varied dramatically among the twenty sub-Saharan population samples represented in the primary core data set (Figure 3A, Table S7). In general, populations with substantial admixture were observed across sub-Saharan Africa, but admixture proportion varied substantially within geographic regions. At the extremes, one Zambia sample (ZI) had 1.4% inferred admixture among four genomes, while another Zambia sample (ZL) had 84% inferred admixture from the single genome sequenced. A Kruskal-Wallis test for the 14 populations with n≥3 primary core genomes supported a significant effect of population on admixture proportion (P<0.0001).
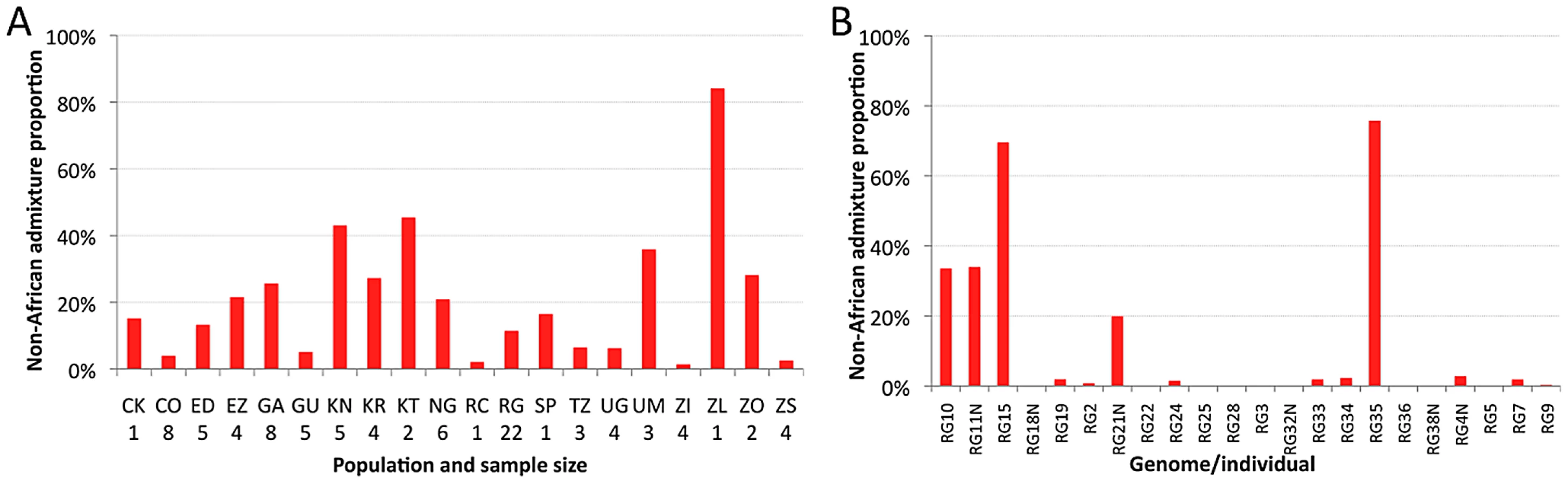
Testing whether admixture might be related to anthropogenic activity, we found that human population size of the collection locality had a strong positive correlation with admixture proportion (Spearman ρ = 0.60; one-tailed P = 0.003; Figure S6). For the seven collection sites with population sizes below 20,000, all but one population sample had an admixture proportion below 7% (the exception, KR, may reflect a higher regional effect of admixture in Kenya). In contrast, for the eight cities with a population above 39,000, admixture proportion was always above 15%. These results mirror previous findings that urban African flies are genetically intermediate between rural African flies and European flies, when population samples from the Republic of Congo [33], [35] and Zimbabwe [34] were examined. Our results suggest that African invasion by cosmopolitan D. melanogaster is not limited to the largest African cities, and has occurred in moderately sized towns and cities across sub-Saharan Africa.
In theory, higher admixture levels in urban African locations could result from either neutral or adaptive processes. If larger cities are more connected to international trade, then selectively neutral immigration would affect urban populations first. However, the large size of admixture tracts (e.g. a mean admixture tract length of 4.8 centiMorgans or 3.8 Mb for the RG sample; Table S7) suggests an unusually rapid spread of cosmopolitan alleles into Africa, which may not be compatible with plausible levels of passive gene flow. We used the method of Pool and Nielsen [36] to estimate, for the RG sample, the parameters of a two epoch migration rate change model. This method found the highest likelihood for a change in migration 59 generations before present, with near-zero migration before this time (point estimate 1.2×10−8), and an unscaled migration rate of 0.0010 since the change. It is not clear whether a neutral model invoking thousands of immigrants per generation should be viewed as realistic. Note that the rate of admixture would have to be higher yet if this small Rwandan town was not the point of African introduction for cosmopolitan immigrants.
Alternatively, cosmopolitan admixture into sub-Saharan D. melanogaster could be a primarily adaptive phenomenon. Certain cosmopolitan alleles might provide a selective advantage in modern urban environments and may now be favored in modernizing African cities, but may be neutral or deleterious in rural African environments. Or, some cosmopolitan genotypes (such as those conferring insecticide resistance [37]) may now be advantageous in both urban and rural African environments, but have thus far spread primarily into urban areas. In either scenario, there is still a role for demography (i.e. migration rates within Africa) in governing the geographic spread of cosmopolitan alleles into African environments in which they are adaptive.
Intra-population variability in cosmopolitan admixture proportion
Perhaps more striking than the between-population pattern of admixture are the stark differences in ancestry observed within populations. This individual variability is well-illustrated by the RG sample (Figure 3B), but similar patterns are also observed in other populations (Table S8). Among the 22 RG primary core genomes, nine have no inferred admixture at all, eight others have less than 3% admixture, while the other five genomes contain 20–76% admixture. Based on forward simulations with recombination and migration [36], the observed variance among genomes in cosmopolitan admixture proportion for the RG sample was found to be unlikely under the point estimates of demographic parameters reported above (one-tailed P = 0.02).
The unexpectedly high variance in admixture proportion may require a combination of biological explanations. Inversion frequency differences between African and introgressing chromosomes would reduce the rate of recombination, potentially keeping admixture in longer blocks. However, the genome-wide prevalence of long admixture tracts (including in regions that do not overlap common inversions) makes this explanation incomplete at best.
Alternatively, African populations may be subject to local heterogeneity for any number of environmental factors, and cosmopolitan alleles may confer a greater preference for and/or fitness in specific microhabitats. Such differences might provide a degree of spatial isolation between flies with higher and lower levels of admixture. However, the RG sample was collected from a handful of markets, restaurants, and bars in the center of the relatively small town of Gikongoro, Rwanda (an area less than 200 m across), and it's not clear whether any meaningful isolation could exist on this scale.
Finally, sexual selection may play a role in generating this pattern. African strains of D. melanogaster are known to display varying degrees of “Z-like” mating behavior, in which females discriminate against males from “M-like” strains, which include cosmopolitan populations [38], [39]. Hence, one would expect many African females to avoid mating with males carrying the cosmopolitan alleles responsible for the M phenotype. And indeed, mating choice experiments [33] found that matings between rural Brazzaville females and urban (apparently admixed) Brazzaville males were much less frequent than homogamic pairings. This phenomenon might help to explain the prevalence of admixture in only a subset of genomes in RG and other samples. Further empirical and predictive studies will be needed to assess the ability of these and other hypotheses to explain the inferred patterns of cosmopolitan admixture among sub-Saharan genomes.
Intra-genomic variability in cosmopolitan admixture proportion
If cosmopolitan admixture is partly due to adaptive processes, it may be worthwhile to examine variability in admixture proportion across the genome. Figure 4 shows the number of primary core genomes with admixture probability above 50% for each window analyzed by the admixture HMM. By including admixture tracts from 95 sub-Saharan genomes across all populations, we may lose some population-specific signals, but we gain resolution that would not exist within small samples.
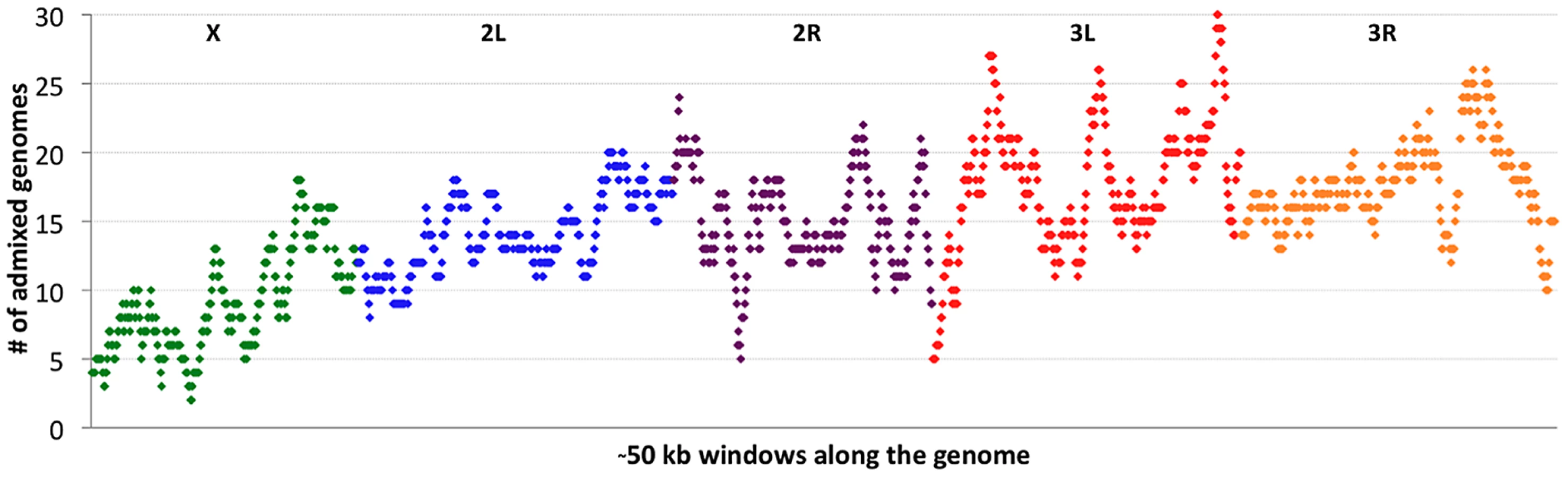
Clear differences were observed between chromosomes in admixture levels. Averaging across all windows, arms 3L and 3R had the highest number of admixed genomes (18.1 and 18.0, respectively), while 2L and 2R were somewhat lower (both averaged 14.7). Both autosomes, however, were considerably more admixed than the X chromosome, which averaged just 9.3 admixed genomes per window. A qualitatively consistent pattern has been reported [34] in which cosmopolitan admixture was detected on the third chromosome but not the X chromosome in a sample from Harare, Zimbabwe.
A lesser contribution of the X chromosome to cosmopolitan admixture might be expected if males contributed disproportionately to introgression. However, the mating preferences described above might be expected to yield the opposite result, suppressing genetic contributions from cosmopolitan males into African populations. Additionally, the loci responsible for the M/Z behavioral polymorphism are thought to reside primarily on the autosomes [38], which should impede autosomal introgression rather than X-linked introgression. Another explanation for the deficiency of X-linked admixture is more efficient selection due to the X chromosome's hemizygosity [40]. The X chromosome might have experienced a higher rate of “out-of-Africa” selective sweeps [12], and even though some cosmopolitan adaptations may now be favored in Africa, it is conceivable that the X chromosome contains a greater density of cosmopolitan alleles that are still deleterious in sub-Saharan Africa and limit X-linked introgression. Even if cosmopolitan alleles that remain deleterious in Africa occur at similar rates on the X chromosome and autosomes, selection might be more effective against introgressing X chromosomes. Alternatively, the X chromosome's higher recombination rate may lead advantageous X-linked cosmopolitan alleles to introgress within smaller chromosomal blocks. The recombination rate difference predicted by mapping crosses [28] will be magnified by the lack of recombination in males, and perhaps also by the autosomes' generally higher levels of inversion polymorphism [41], which should decrease autosomal recombination rates in nature and increase X chromosome recombination (due to the interchromosomal effect [42]).
Considerable variation in the proportion of admixed individuals was also apparent within chromosomes. For example, the X chromosome's dearth of admixture was most dramatic for the telomere-proximal half of its windows (average 6.9 admixed genomes) and less severe for the centromere-proximal half (average 11.7). On a finer scale, the proportion of admixed genomes showed relatively narrow genomic peaks and valleys (Figure 4), with the most extreme admixture levels often limited to intervals on the order of 100 kb. If the adaptive hypothesis of cosmopolitan admixture is correct, genomic peaks and valleys of admixture could include cosmopolitan loci that are advantageous and deleterious, respectively, in sub-Saharan Africa. We return to the specific content of these intervals later, in the context of out-of-Africa sweeps.
Principal Components Analysis
In order to evaluate the effectiveness of admixture identification and to examine geographic gradients of genetic variation, principal Components Analysis (PCA) [43] was applied to admixture-filtered and unfiltered data. In both cases, the first principal component clearly reflected cosmopolitan versus African ancestry. Comparison of these results suggested that our admixture detection method had successfully filtered most, but not all, cosmopolitan admixture from sub-Saharan genomes (Figure 5A). For example, RG35 was by far the most admixed genome in its Rwanda population sample, with a pre-filtering -PC1 of 0.153. After filtering, its PC1 dropped to −0.001 – a considerable improvement, although slightly higher than the population average of −0.049. Hence, a minority of admixture may remain undetected, and for analyses that may be especially sensitive to low levels of admixture, users of the data could opt to exclude genomes with higher levels of detected admixture.
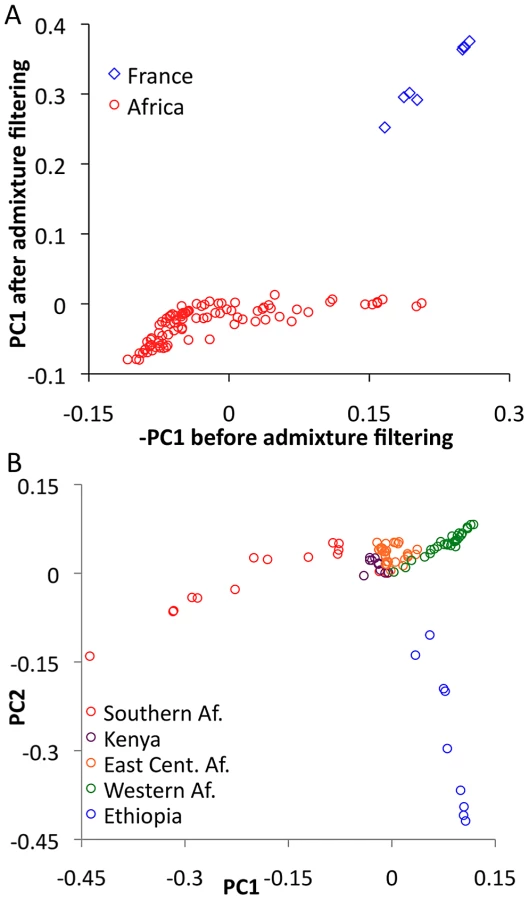
Focusing on PCA from admixture-filtered sub-Saharan data, PC1 separated southern African populations from western African and Ethiopian populations, with eastern African samples having intermediate values (Figure 5B). PC2 mainly distinguished Ethiopian samples from all others, while subsequent principal components lacked obvious geographic patterns (Table S9).
Geographic patterns of sub-Saharan genetic diversity
Nucleotide diversity was evaluated for windows and for full chromosome arms, in terms of both absolute and relative π (the latter based on comparison with the RG sample). The use of relative π allowed unbiased comparisons of diversity involving populations with incomplete genomic coverage of admixture-filtered data, and it enabled populations lacking two or more genomes with >25X depth to be considered by using RG genomes with similar depth for comparison (see Materials and Methods).
Under simple demographic scenarios of geographic expansion, populations with the highest genetic diversity are the most likely to reflect the geographic origin of all extant populations. Hypotheses for the ancestral range of D. melanogaster within sub-Saharan Africa have ranged from western and central Africa (based on biogeography [16]) to eastern and southern Africa (based on a smaller sequence data set [18]). Among 19 African populations, the greatest diversity was found in the ZI sample collected from Siavonga, Zambia (Figure 6; Table 1; Table S10), followed by the geographically proximate ZS and ZO samples. The inferred nucleotide diversity of ZI (0.70%; 0.83% for higher recombination regions) is lower than estimates for geographically similar samples based on multilocus Sanger sequencing [13], and slightly lower than a recent population genomic analysis [28], but higher than an earlier population genomic estimate of θ [44]. While differences in the genomic coverage of these data sets may help to explain some differences, mapping and consensus-calling biases against non-reference reads may also play a role. Such factors are not expected to have a dramatic impact on comparisons of diversity levels between African populations. Hence, based on the samples represented in our study, southern-central Africa appears to contain the center of genetic diversity for D. melanogaster. Although this hypothesis requires further confirmation, these results are consistent with a southern African origin for D. melanogaster.
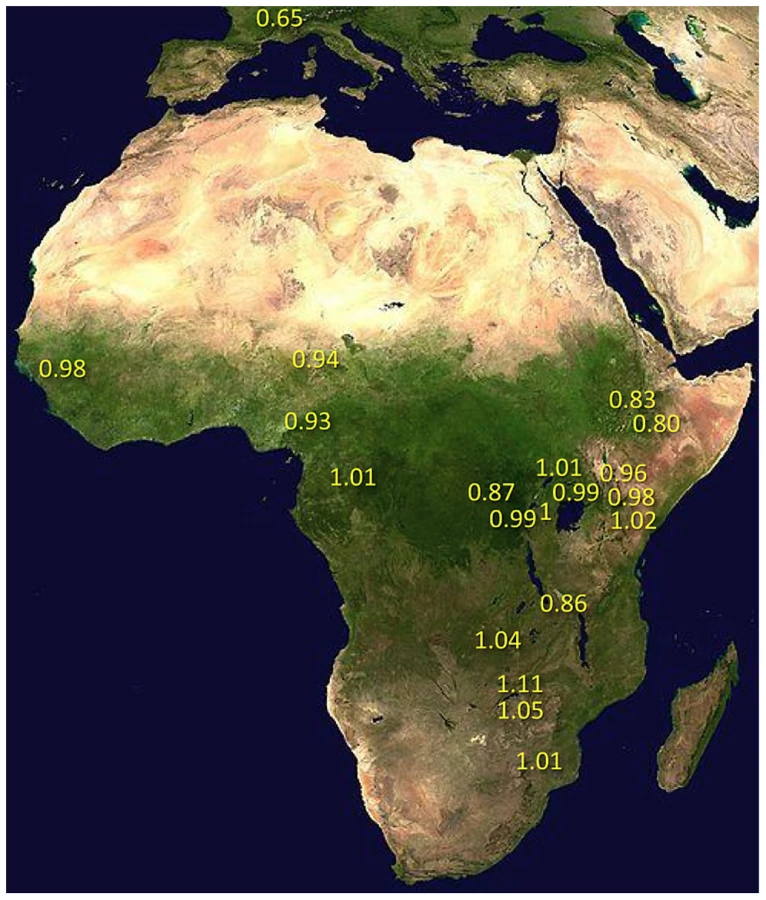
Much of Zambia and Zimbabwe is characterized by a subtropical climate and seasonally dry Miombo and Mopane woodland. Whether this landscape might reflect the original environment of D. melanogaster is unclear, because the species has never been collected from a completely wild environment [16] and the details of its transition to an obligately human-commensal species are unknown [19]. Compared with related species, African strains of D. melanogaster have superior resistance to desiccation [45] and temperature extremes [46]. These characteristics would be predicted by an evolutionary origin in subtropical southern Africa, as opposed to humid equatorial forests.
Most populations from eastern Africa (including Kenya, Rwanda, and Uganda) had modestly lower diversity compared to Zambia and Zimbabwe, while western populations (including Cameroon, Guinea, and Nigeria) showed an additional slight reduction. The two Ethiopian samples showed the lowest variation among African populations, with roughly three quarters the diversity of ZI, potentially indicating a bottleneck during or since the species' occupation of Ethiopia. The distinctness of Ethiopian samples was also indicated by an analysis of mitochondrial and Wolbachia genomes from these same genomes [47]. Otherwise, only two population samples had reduced diversity relative to the overall geographic pattern described above, and one of these (CK) had limited pairwise comparisons in the admixture-filtered data.
The other sample with locally reduced variation, TZ, displays an unusual pattern of diversity loss on chromosome arms X and 2L specifically (Table 1), associated with all three sampled genomes carrying inversions In(1)A and In(2L)t [48]. Similarly, two of the three Kenya samples (KN and KR) show reduced diversity on arm 2L only, also apparently in association with In(2L)t [48]. These results suggest the possibility that selection on polymorphic inversions, which are common in sub-Saharan populations [41], can be an important determinant of genome-scale diversity levels. Although this hypothesis is contrary to some theoretical predictions [49] and empirical findings [50] that would lead one to expect the effects of inversions to be mainly restricted to breakpoint regions, it is supported by an analysis of inversion polymorphism and linked variation in the genomes studied here [48].
Chromosomal diversity in a non-African population
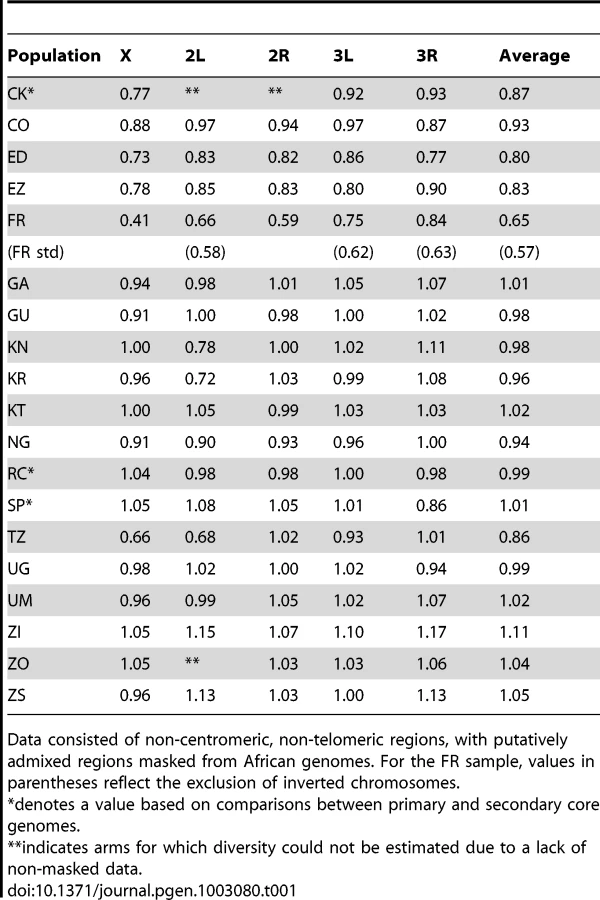
Consistent with previous work [12], [13], [51], variation for the cosmopolitan sample (FR) is much more strongly reduced on the X chromosome relative to the autosomes (Table 1). However, further genomic patterns in the ratio of πFR to πRG can be observed (Figure 7). This diversity ratio ranges from below 0.2 (at the X telomere) to above 1 (for a window on arm 3R), with similar patterns observed if πFR is instead compared against πZI (Figure S7). Diversity ratios on autosomal arms showed distinct differences: FR retains 59% of the RG diversity level on arm 2R but 84% on arm 3R (Table 1).
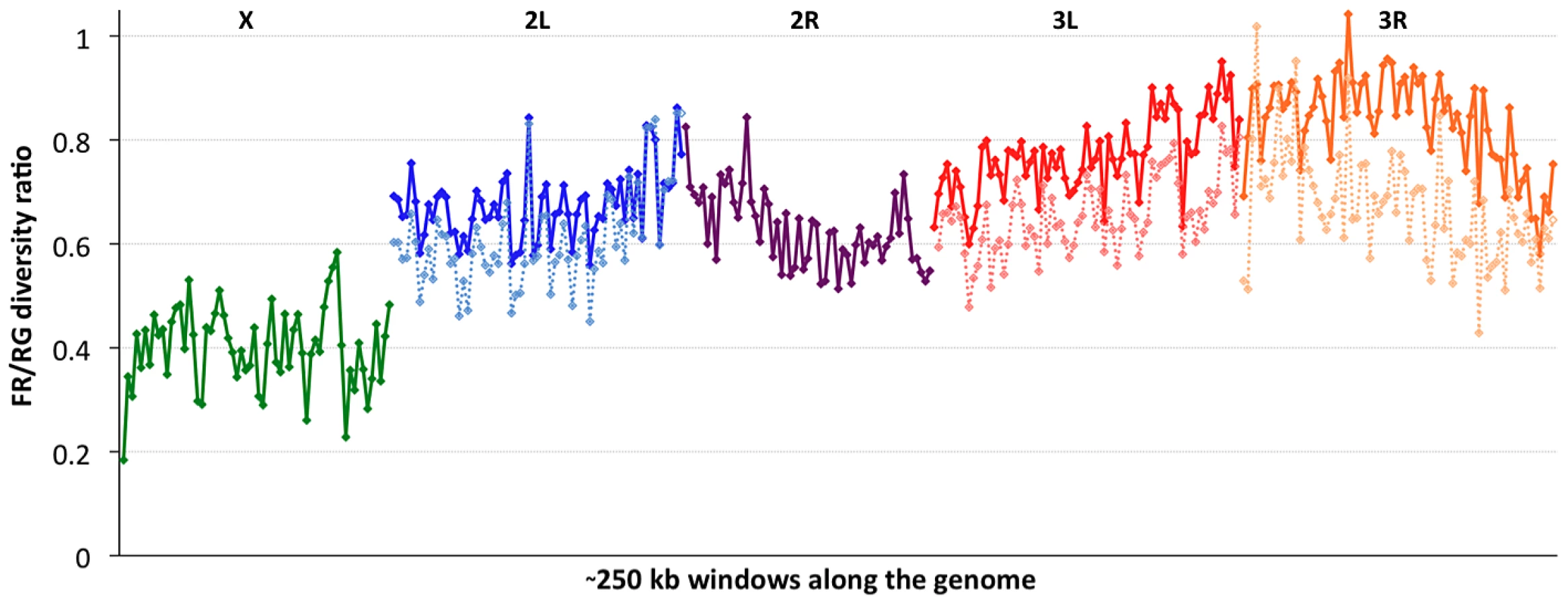
Based on the inversions identified for each genome [48], we examined the influence of inversions on chromosome arm-wide diversity by recalculating πFR and πRG using standard chromosome arms only. For the RG sample, the exclusion of inversion-carrying arms had negligible influence on diversity, except that the inclusion of In(3R)P (present in four of 22 genomes) increased πRG on arm 3R by 4% (Table S10). More dramatic contrasts were observed for the FR sample, in which inversions were found to result in arm-wide diversity increases of 10% on arm 2L (due to one of eight FR genomes carrying In(2L)t) and 18% on arm 3L (due to a pair of In(3L)P chromosomes). As further detailed in a separate analysis [50], arm 3R was even more strongly affected, with a 29% diversity increase due to the presence of In(3R)P (in three of eight genomes), In(3R)K and In(3R)Mo (one genome each). Although the French sample only contains inversions on these three arms, they contribute to a 12% genome-wide increase in nucleotide diversity.
In light of the above observations, it is possible that inversions have had important effects both in reducing chromosome arm-wide diversity (for the Tanzania and Kenya populations) and also in elevating it (for non-African autosomes). As further suggested in a separate analysis [48], the spatial scale of increased diversity associated with inversions in the France sample (Figure 7) may indicate a recent arrival of inverted chromosomes from one or more genetically differentiated populations. Given that similar levels of gene flow are not indicated by polymorphism on chromosome arms lacking inversions, the spread of genetically divergent inverted chromosomes into France may have been primarily driven by natural selection. In light of their powerful elevation of πFR, inverted chromosomes in this sample may have originated from a more genetically diverse African or African-admixed population. Similarly, the more modest elevation of πRG associated with In(3R)P might indicate the recent introgression of these inverted chromosomes from a genetically differentiated population. However, the nature of selective pressures acting on inversions in natural populations of D. melanogaster remains largely unknown.
Without inversions, relative πFR for autosomal arms ranged from 0.58 to 0.63, with chromosome 3 showing higher values than chromosome 2. In light of the above hypothesis to account for the presence of divergent inverted chromosomes in the France sample, some of the remaining differences in relative πFR among inversion-free chromosomes might stem from recombination between standard chromosomes and earlier waves of introgressing inverted chromosomes. Alternatively, given that D. melanogaster autosomes frequently carry recessive deleterious mutations [52], associative overdominance during the out-of-Africa bottleneck might have favored intermediate inversion frequencies [53]–[55]. This hypothesis is mainly plausible in small populations [56], which may have existed due to strong founder events during the out-of-Africa expansion [57]. Given the opportunity for recombination between standard and inverted chromosomes since that time, past associative overdominance related to inversions (or centromeric regions) might contribute to the modest difference in relative πFR between inversion-free second and third chromosomes, as well as the larger gap between both autosomes and the X chromosome.
The ratio of relative πFR for the X chromosome versus the inversion-free autosomes appears consistent with some previously explored founder event models [57] if chromosomes X and 2 are compared (ratio = 0.692, compared to a minimum of 0.669 in the cited study), but not if chromosome 3 is examined instead (ratio = 0.646). Some studies have concluded that the difference between X-linked and autosomal diversity reductions in cosmopolitan D. melanogaster exceeds the predictions of demographic models involving population bottlenecks and/or a shift in sex-specific variance in reproductive success [12], [13]. Instead, the X chromosome's disproportionate diversity reduction might result from more efficient positive selection on this chromosome (due to male hemizygosity [40]) during the adaptation of cosmopolitan populations to temperate environments. However, it appears relevant that the above studies examined autosomal loci on chromosome 3, but not chromosome 2. Further theoretical, simulation, and inferential studies to elucidate the relative influence of selection, demography, and inversions on the X chromosome and autosomes is needed before their relative contribution to diversity in cosmopolitan D. melanogaster can be clearly understood.
Genetic structure and expansion history
Levels of genetic differentiation between populations were evaluated in terms of Dxy and FST [58] for each chromosome arm. In order to minimize the effects of any residual admixture in the filtered data, only genomes with admixture proportion below 15% were included. Populations with sufficient data for this analysis included CO, ED, FR, GA, GU, KR, NG, RG, TZ, UG, ZI, and ZS. Within Africa, FST values on the order of 0.05 were typical (Table 2). Geographically proximate population pairs often had lower FST (at minimum, a value of 0.009 between ZI and ZS). Comparisons involving the ED sample gave uniformly higher FST than other African comparisons (median 0.147), consistent with the loss of diversity observed for Ethiopian samples. As expected, comparisons of African samples with the European FR sample yielded the highest FST values (median 0.208). Genetic differentiation at putatively unconstrained short intron sites [59], [60] showed similar patterns (Table S11), but as expected, magnitudes of Dxy and π were more than twice as high as for all non-centromeric, non-telomeric sites (for ZI, short intron π = 0.0194).
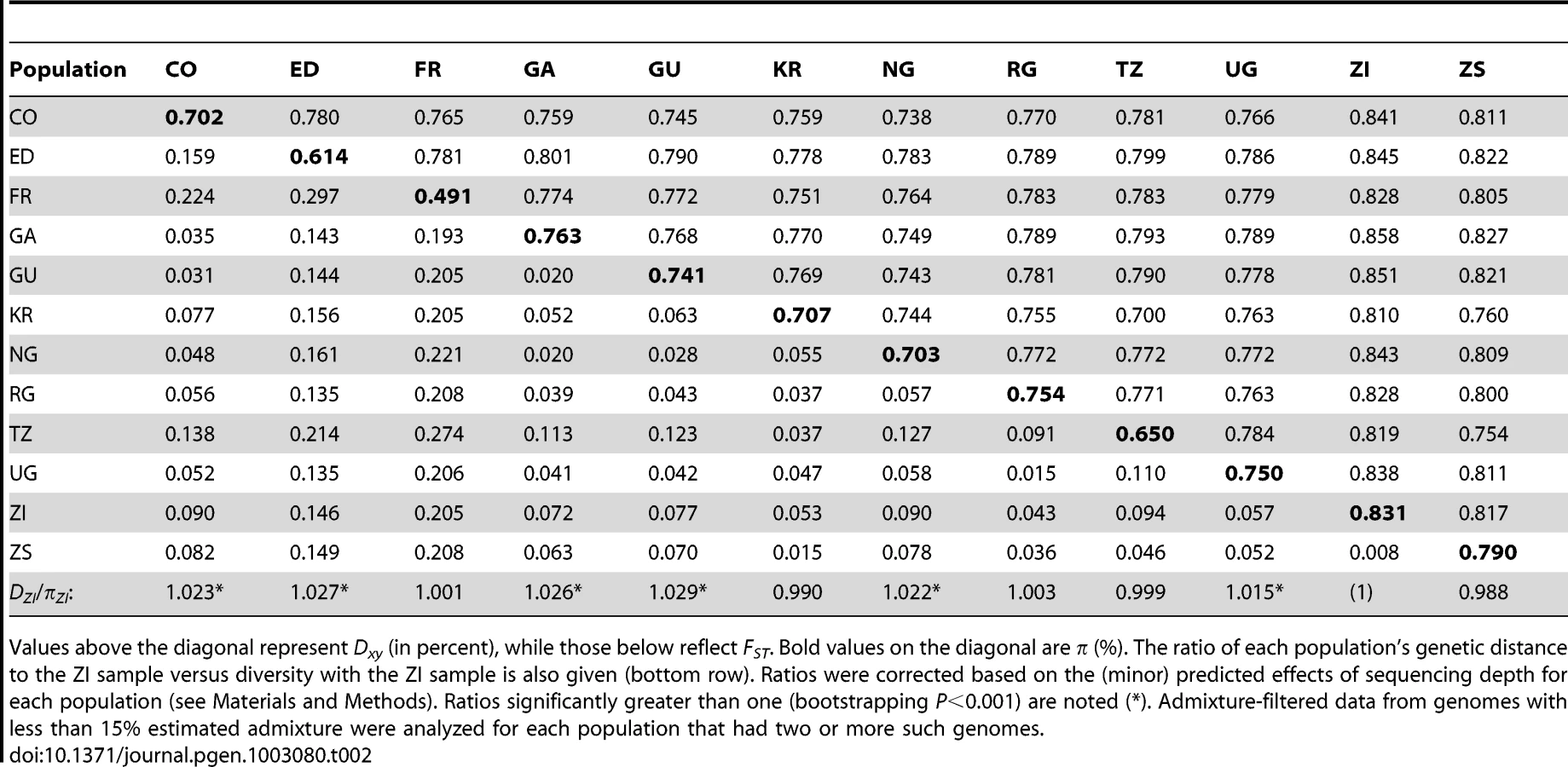
In order to assess the compatibility our data with a model of geographic expansion from southern Africa, we examined the ratio of each population's DZI (average pairwise genetic distance, or Dxy, between this population and the ZI sample) and πZI. This ratio will be near 1 if a population's genomes are no more divergent from ZI genomes than ZI genomes are from each other, consistent with the recent sampling of this population's diversity from a ZI-like ancestral population. In contrast, ratios exceeding 1 indicate that a population contains unique genetic diversity not present in ZI. Populations from eastern Africa (KR, RG, TZ, UG) and Europe (FR) had ratios compatible with a recent ZI-like origin (Table 2). However, populations from western Africa (CO, GA, GU, NG) and Ethiopia (ED) showed modest levels of unique variation. The highest ratio, for Guinea (GU), indicated a 2.9% excess of DZI over πZI. Elevated ratios could indicate a relatively ancient occupation of at least some of the above regions (perhaps on the order of tens of thousands of years). Alternatively, under the hypothesis of an expansion from southern Africa, these regions may have received a genetic contribution from a different part of a structured southern African ancestral range (e.g. migration into Gabon and western Africa from Angola, which also contains Miombo woodlands but has not been sampled).
Examination of genomewide genetic differentiation may also shed light on the sub-Saharan origins of cosmopolitan D. melanogaster. Geographic hypotheses for expansion of D. melanogaster from sub-Saharan Africa have ranged from a Nile route starting from the equatorial rift zone [18] to a more western crossing of the Sahara via formerly wetter areas of “Paleochad” [16]. A simple prediction is that the sub-Saharan samples most closely related to the cosmopolitan source population should show the lowest values of Dxy and FST relative to the cosmopolitan FR sample. However, even low levels of undetected cosmopolitan admixture in sub-Saharan genomes could obscure this signal, and so only genomes with <15% detected admixture were considered below. Among the eleven African populations analyzed (see above), the Kenyan KR sample showed the lowest genome-wide DFR (Table 2) and would have had the lowest FR FST if not for its anomalous pattern of variation for arm 2L (Table S11). However, KR is the sample with the highest proportion of detected cosmopolitan admixture, which clouds the interpretation of these results. After KR, the lowest DFR values come from the western group of samples (NG, CO, GA, and GU), of which two (CO and GU) had relatively low levels of detected admixture. Despite its northeast sub-Saharan location, the Ethiopian ED sample does not appear to represent a genetic intermediate between cosmopolitan and other sub-Saharan populations, and may instead represent a separate branch of this species' geographic expansion. Further sampling and analysis may be needed to obtain compelling evidence regarding the geographic origin of cosmopolitan D. melanogaster.
One scenario for the sub-Saharan expansion of D. melanogaster is illustrated by the geographic fit of a simple neighbor-joining population tree based on Dxy values (Figure 8; Figure S8). This tree is consistent with the hypothesis of a southern Africa origin for D. melanogaster, with an initial expansion into eastern Africa, followed by offshoots reaching Ethiopia, the palearctic (northern Africa and beyond), and western Africa. Of course, even after the filtering of cosmopolitan admixture, a tree-like topology is not likely to fully describe the history of sub-Saharan D. melanogaster populations. However, the history described above seems consistent with levels and patterns of population diversity (Figure 6; Table 2), and may capture some important general features of the species' history.
Even if the general expansion history described above ultimately proves to be accurate, many historical details await clarification. Diversity differences among African populations could indicate population bottlenecks during a sub-Saharan range expansion, and population growth during such an expansion is also possible. Further analysis of population genomic data is also needed to establish whether ancestral range populations have also been affected by population growth [23] or a bottleneck [21]. Lastly, although migration within Africa has not erased the observed diversity differences and genetic structure, the historical and present magnitudes of such gene flow are not clear. The quantitative estimation of historical parameters may be addressed by detailed follow-up studies. However, for a species like D. melanogaster, in which very large population sizes may allow relatively high rates of advantageous mutation and efficient positive selection, one concern is that the effects of recurrent hitchhiking may be important on a genomewide scale [27], [28], [61], [62]. Hence, the application of standard demographic inference methods to random portions of the D. melanogaster genome (or even putatively unconstrained sites) may yield estimates that are biased by violations of the assumption of selective neutrality. Under the assumption of demographic equilibrium, Jensen et al. [62] estimated a ∼50% reduction in diversity due to positive selection for Zimbabwe D. melanogaster, and selective sweeps may have similarly important influences on the means and variances of other population genetic statistics as well. Hence, further methodological development may be needed before accurate demographic estimates can be obtained for species in which large population sizes facilitate efficient natural selection.
Influence of recombination and selection on genetic variation
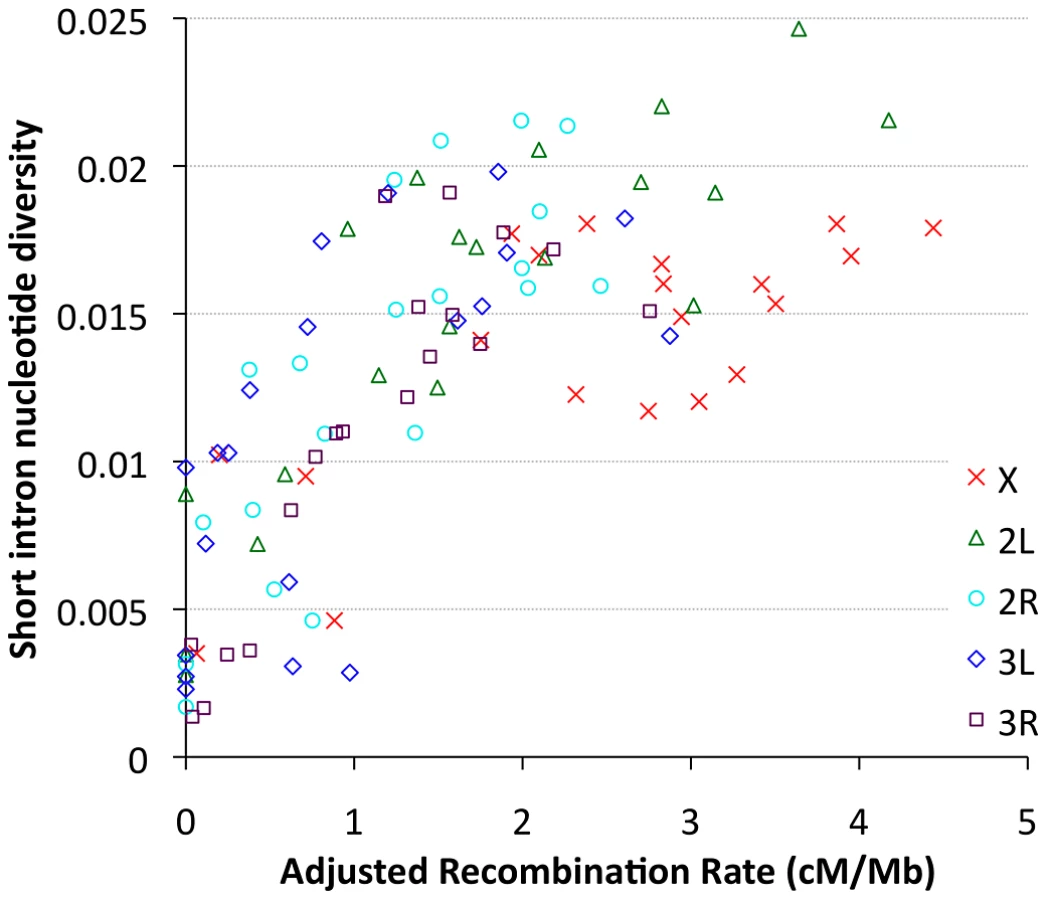
Focusing on our largest population sample (22 primary core RG genomes), we investigated relationships between genetic diversity and mapping-based recombination rate estimates [28]. To minimize the effects of direct selective constraint on the sites examined, we focused on the middles of short introns (bp 8 to 30 of introns ≤65 bp in length), which are among the most polymorphic and divergent sites observed in the Drosophila genome [59], [60]. Since each 23 bp intronic locus is too small to be considered individually, we show broad-scale patterns of diversity from all relevant sites within a given cytological band. Consistent with previous findings [9], strong relationships between recombination and variation were observed for all chromosome arms (Figure 9), with Pearson's r ranging from 0.68 (for 3L) to 0.95 (for 2R), with P = 0.0005 or lower for all arms (Table S12). Curiously, bp position along the chromosome arm was a stronger predictor of diversity than estimated recombination rate for arms 3L and 3R (Table S12), which could reflect imprecision in recombination rate estimates for chromosome 3, or the influence of polymorphic inversions on recombination in nature. Across all autosomal arms, the strongest correlation between recombination and diversity was for low rates of crossing-over (adjusted rate below 1 cM/Mb, equivalent to an unadjusted 2 cM/Mb rate, Pearson r = 0.56 and P = 0.0002). However, a strong correlation persisted above this threshold as well (Pearson r = 0.44, P = 0.002). Correlations within these categories were not significant for the X chromosome, potentially due to smaller numbers of chromosome bands, especially for the low recombination category (n = 4). Overall, the above results are consistent with the well-supported role for natural selection in reducing variation in regions of low recombination. However, the relative contributions of specific selection models such as hitchhiking [10] and background selection [11] to this pattern have not been quantitatively estimated.
Examining the RG sample's allele frequencies at short intron sites, we observed an excess of singleton polymorphisms (sites with a minor allele count of 1) for all chromosome arms relative to the predictions of selective neutrality and demographic equilibrium (Figure 10A). The degree of this excess varied among chromosome arms: compared to a null expectation of 31% singleton variants, the autosomal arms ranged from 33% to 37%, while the X chromosome had 44% singletons. The general excess of rare alleles could reflect population growth, as suggested for a Zimbabwe population sample [23], and growth has some potential to influence X-linked and autosomal variation differently [63]. Recurrent hitchhiking may contribute to the genomewide excess of rare alleles [64]. Under this hypothesis, the difference in singleton excess between the X chromosome could reflect more efficient X-linked selection due to hemizygosity [40]. Without a difference in the rate of X-linked and autosomal adaptation, this contrast could instead result from a greater fraction of X-linked selective sweeps acting on new beneficial mutations, with relatively more autosomal sweeps via selection on standing variation. The autosomes may have more potential to harbor recessive and previously deleterious functional variants, and sweeps from standing variation do not strongly influence the allele frequency spectrum [65].
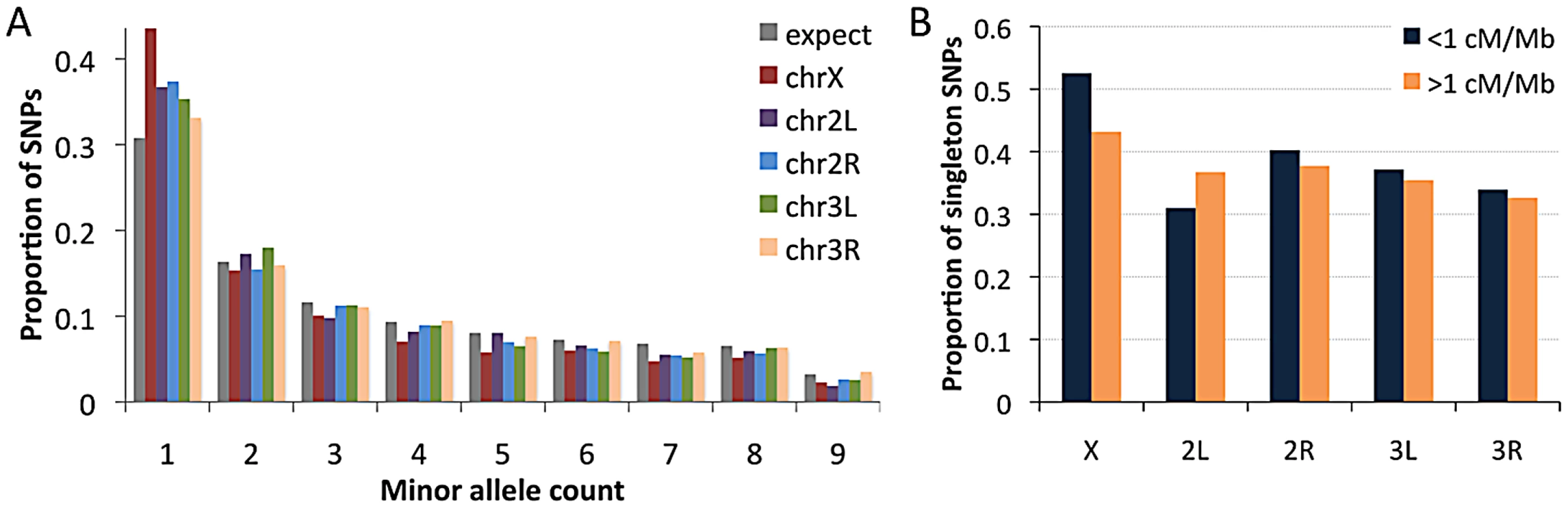
We also used short intron allele frequencies to conduct a preliminary analysis of the relationship between recombination and rare alleles. Specifically, we tested whether the proportion of singletons among variable sites differed between low recombination regions (defined here as <1 cM/Mb) and moderate to high recombination regions (>1 cM/Mb). No clear relationship between recombination and allele frequency was observed above this cutoff (results not shown). For the 1 cM/Mb threshold, the X chromosome showed an elevated proportion of singletons in the low recombination category (53% vs. 43%; Pearson χ2 P = 0.032; Figure 10B). Data from the autosomes are inconclusive: while three arms show non-significant trends toward more rare alleles in low recombination regions (Figure 10B), arm 2L showed a significant pattern in the opposite direction (30% vs. 36%; P = 0.025), possibly reflecting specific evolutionary dynamics of the 2L centromere-proximal region. The X chromosome result is qualitatively consistent with the predictions of the recurrent hitchhiking model [64] and some (but not all) previous findings from D. melanogaster [51], [66], [67]. Under this hypothesis, the lack of a comparable autosomal pattern might indicate a lesser influence of classic selective sweeps on the autosomes relative to the X chromosome, or a greater effect of inversion-related selection on the autosomes obscuring predictions of the recurrent hitchhiking model. Background selection may also increase the proportion of singletons [68], [69], although a greater X-linked effect of background selection has not been suggested. Further study is needed to quantify the influence of positive and negative selection at linked sites on nucleotide diversity and allele frequencies in the D. melanogaster genome.
Linkage disequilibrium and its direction
Linkage disequilibrium (LD) was examined using a standard correlation coefficient (r2) between single nucleotide polymorphism (SNP) pairs, and also via the directional LD metric rω [70], [71]. The rω statistic is positive when minor frequency alleles at two sites tend to occur on the same haplotype, negative if they tend to be on different haplotypes. Although we lack a comprehensive understanding of the evolutionary forces capable of influencing rω, it is known that hitchhiking strengthens positive rω (since recombination near a selective sweep leaves groups of positively linked SNPs [72]), while negative rω may result from epistatic interactions among beneficial or deleterious alleles [70]. Empirical data from the RG sample was compared against neutral simulations with equilibrium demographic history. Importantly, equilibrium may not accurately reflect the history of the RG sample: recent population growth may have occurred, and the RG sample's modest diversity reduction compared to the ZI sample may imply a mild population bottleneck. Although the full effects of demography can not be eliminated by any simple procedure, we can reduce the influence of growth or other forces responsible for this population's excess of singleton polymorphisms by excluding singletons from the empirical and simulated data.
In general, an excess of LD was observed over neutral, equilibrium predictions for all chromosome arms (Figure 11A). The X chromosome's lower LD is consistent with its higher average recombination rate (54% higher for the regions examined [28]). The RG pattern contrasts with data from a North American population, which showed elevated X-linked LD [28], [29] that likely reflects a stronger influence of demography and possibly selection on the X chromosome during the species' out-of-Africa expansion. For the RG sample, the X chromosome's LD excess was largely confined to the 10–100 bp scale. In contrast, autosomal arms showed an excess of LD at all scales 10 bp and above (Figure 11A). Since the simulations account for differences in average (inversion-free) recombination rate between the X and autosomes, the autosomes' more pronounced LD excess could result from a stronger influence of inversions on these arms. As noted above, the autosomes' higher inversion polymorphism should reduce autosomal recombination rates in nature and increase X chromosome recombination rates. Arm 3R contains the largest number of common inversions in Africa [41], and LD for this arm is by far the highest. Arm 3R's somewhat lower average recombination rate (7–27% lower than other autosomal arms for the analyzed regions) may contribute to this pattern as well. The above observations regarding LD are concordant with estimates of the population recombination rate for the RG sample, which are elevated for the X chromosome (in spite of its potentially lower population size) and reduced for 3R [73].
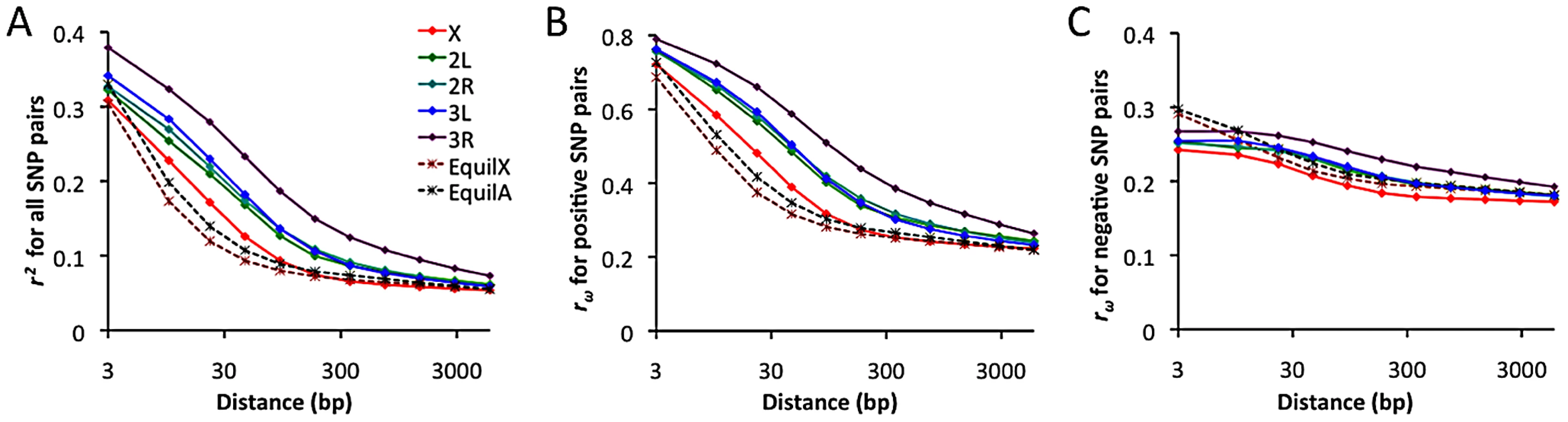
Notably, the observed LD excess is driven entirely by SNP pairs with positive rω (Figure 11B), while negative SNP pairs show no departure from equilibrium expectations (Figure 11C). Although cosmopolitan admixture has been largely removed from the analyzed data set, it remains possible that demographic events of this nature might inflate positive LD specifically. Inversions may well play a role in boosting positive LD, since inversion-associated polymorphisms may often be present at similar frequencies on the same haplotypes. However, given the excess of LD on all chromosome arms and on relatively short spatial scales, it is not yet clear whether inversions are a sufficient explanation. Recurrent hitchhiking may also contribute to the genome-wide excess of positive LD [72]. Further studies will be needed to evaluate the compatibility of specific hypotheses with genome-wide LD patterns.
Potential targets of selective sweeps in a Rwanda sample
Identifying the genes and mutations underlying Darwinian selection is an important aspect of evolutionary biology, and of population genomics in particular. The lack of a precise demographic model limits our ability to formally reject the null hypothesis of neutral evolution for specific loci, since certain demographic models can mimic the effects of selective sweeps [74]. However, we have still sought to learn about general patterns of directional selection in the genome by conducting a series of local outlier analyses to detect unusual patterns of allele frequencies within and between populations that are consistent with recent adaptive evolution. These outlier analyses necessarily involve a strong assumption about the proportion of the genome affected by selection. However, the enrichment analyses we perform on these outliers should be robust to some level of random false positives within the outliers, and should still be informative if not all adaptive loci are detected.
We searched for putative signals of selective sweeps in the RG sample using a modified version of the SweepFinder program [75], [76] that looks for both allele frequency spectra and diversity reductions consistent with recent selective sweeps. As further described in the Materials and Methods section, we analyzed the RG data in windows and used the Λmax statistic in an outlier framework, rather than making an explicit assumption regarding the appropriate demographic null model – as would have been required for typical simulations defining statistical significance. Here, we focus on the most extreme 5% of windows from each chromosome arm. After merging neighboring outlier windows, a total of 343 outlier regions were obtained (Table S13). For each outlier region, the gene with the closest exon to the Λmax peak was recorded. Genes within extreme outlier regions included Ankyrin 2 (cytoskeleton, axon extension), Girdin (actin filament organization, regulation of cell size), Laminin A (behavior, development, meiosis), narrow abdomen (ion channel, circadian rhythm), Odorant receptor 22a [77], and ribosomal proteins S2 and S14b (separate regions). Several strong outliers corresponded to genes also implicated in a recent genome scan based on outliers for low polymorphism relative to divergence [28], including bendless (axonogenesis, flight behavior) CENP-meta (mitotic spindle organization, neurogenesis), female sterile (1) homeotic (regulation of transcription), Heterogeneous nuclear ribonucleoprotein at 27C (regulation of splicing), loquacious (RNA interference, nervous system development, germ-line stem cell division), and no distributive junction (meiotic chromosome segregation).
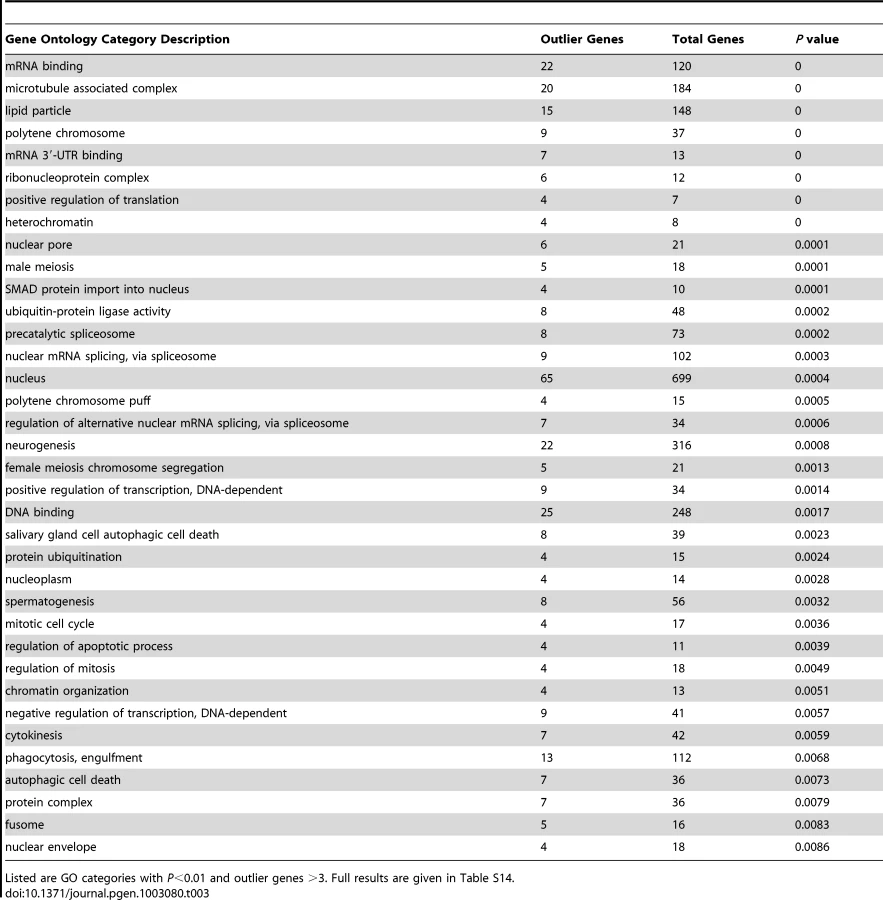
Despite a similar number of outlier regions as the FST analyses described below, the Λmax scan yielded a much larger number of significantly enriched gene ontology categories: 115 categories had P<0.05 based on random permutation of target windows within chromosomal arms (Table 3; Table S14). Consistent with previous results from a population genomic outlier analysis of diversity and divergence [28], numerous biological processes related to gene regulation were observed, including positive and negative regulation of transcription, positive regulation of translation, regulation of alternative splicing, mRNA cleavage, chromatin organization, regulation of chromatin silencing, and gene silencing. Many enriched cellular components (e.g. nucleus, precatalytic spliceosome, mRNA cleavage and polyadenylation complex, ribonucleoprotein complex, heterochromatin, and euchromatin) and molecular activities (e.g. DNA binding, mRNA binding and especially mRNA 3′-UTR binding) were also consistent with a broad importance for regulators of gene expression in recent adaptive evolution. A number of the GO terms listed in Table 3 were also reported from the above-mentioned genome scan [28], including negative regulation of transcription, positive regulation of translation, ribonucleoprotein complex, precatalytic spliceosome, protein ubiquitination, nuclear pore, lipid particle, and spermatogenesis. Other enriched biological processes included oogenesis, neurogenesis, male meiosis and female meiosis chromosome segregation, regulation of mitosis and apoptosis, and phagocytosis. Additional cellular components included microtubule-associated complex, kinetochore, and fusome while enriched molecular activities also included ATP binding and voltage-gated calcium channel activity.
Locally elevated genetic differentiation between African populations
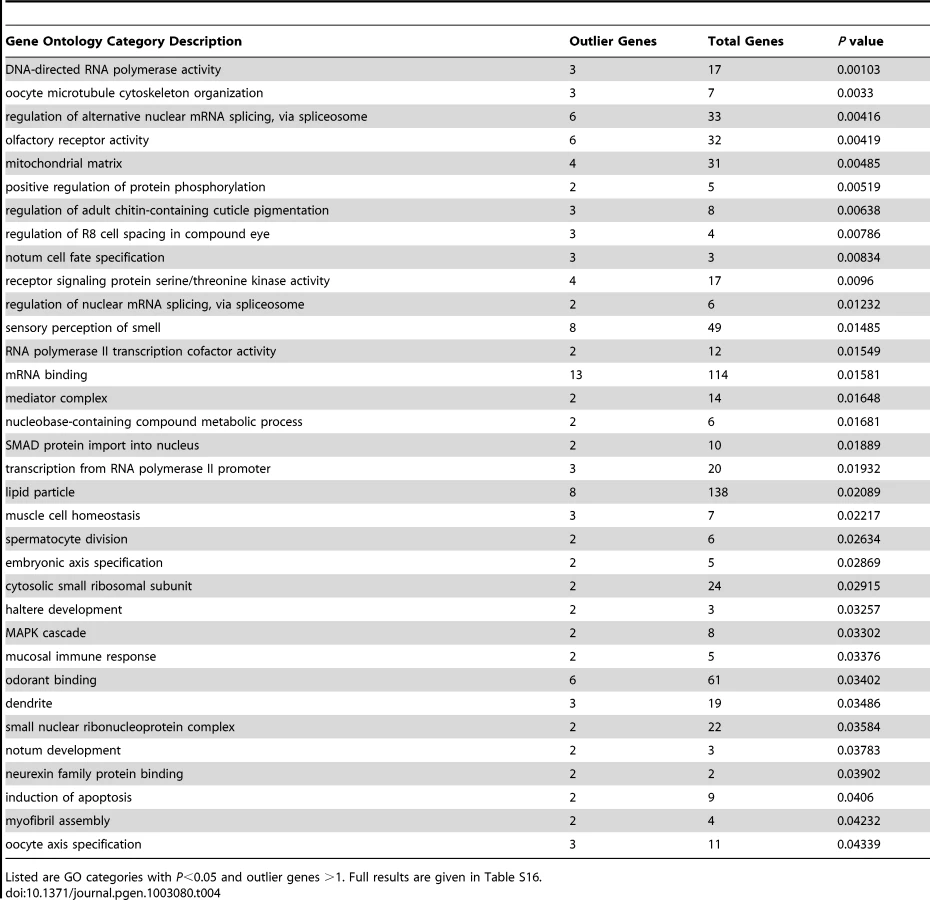
Nine African population samples with larger sample sizes after admixture filtering were included in an analysis of local genetic differentiation. FST was evaluated for each pair of populations, and the mean FST for each window was noted. Examination of the 2.5% highest mean FST values for each chromosome arm and the merging of neighboring outlier windows resulted in 294 outlier regions (Table S15). For each outlier region, the gene with the closest exon to the center of the most extreme window was noted. Genes associated with unusually strong FST outlier regions included Odorant receptor 22b (tandem paralog of the above-mentioned Or22a), Cuticular protein 65Au, Dystrophin, P-element somatic inhibitor, and CG15696 (predicted homeobox transcription factor). Of course, many of the strongest putative signals of adaptive differentiation are wide, and further investigation will be needed to confirm specific targets of selection. Permutation of putative target windows indicated that genes from 34 GO categories were significantly over-represented among our outliers at the P = 0.05 level (Table 4; Table S16). These GO categories included biological processes (e.g. oocyte cytoskeleton organization, regulation of alternative splicing, regulation of adult cuticle pigmentation), cellular components (e.g. mitochondrial matrix, dendrite), and molecular functions (e.g. olfactory receptor activity, mRNA binding).
Locally elevated genetic differentiation between Africa and Europe
A windowed FST outlier approach was also applied to detect loci that may contain adaptive differences between sub-Saharan (RG) and European (FR) populations.
Some of these loci might have had adaptive importance during the expansion of D. melanogaster into temperate environments, but others could reflect recent selection within Africa. A total of 346 outlier regions resulted from analyzing the upper 2.5% tail of Rwanda-France FST (Table S17). Genes associated with strong FST outliers included Or22a (which may be under selection in Africa, see above), CHKov1 (insecticide and viral resistance [78], [79]), ACXC (spermatogenesis), and Jonah 98Ciii (digestion), plus a number of genes involved in morphological and/or nervous system development (e.g. Bar-H1, Death-associated protein kinase related, Enhancer of split, hemipterous, highwire, mastermind, rictor, sevenless, Serendipity δ, and wing blister). Other genes at the center of strong outlier regions were also detected by a genome-wide analysis of diversity ratio between U.S. and Malawi populations [28], including dpr13 (predicted chemosensory function), Neuropeptide Y receptor-like, rugose (eye development), and Sno oncogene (growth factor signaling, neuron development).
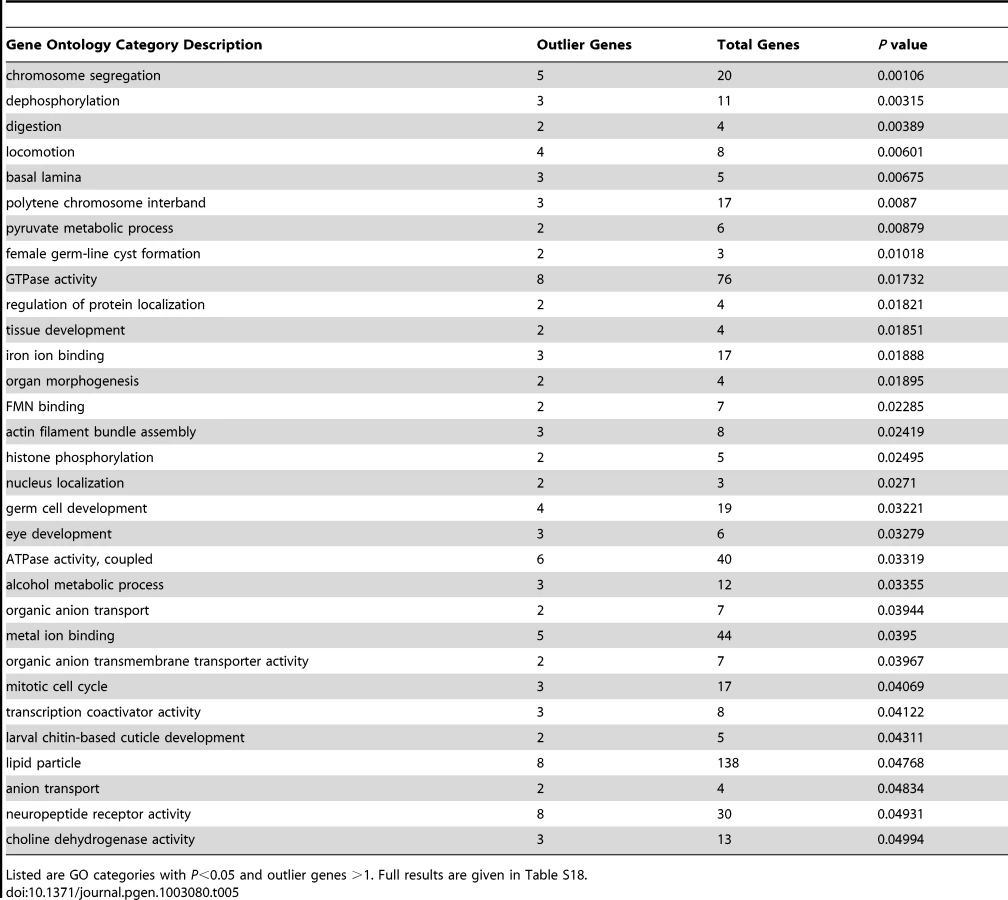
The genes identified in this analysis still yielded 31 significantly enriched GO categories (Table 5; Table S18). Biological processes among these GO categories included chromosome segregation, locomotion, female germ-line cyst formation, histone phosphorylation, and alcohol metabolism. Cellular components included basal lamina and polytene chromosome interband, while molecular activities included transcription coactivators and neuropeptide receptors. The detected GO categories were essentially distinct from those obtained from the diversity ratio analysis of Langley et al. [28]. The lack of overlap may stem at least partially from differences in the statistics and populations used in each analysis. The well-known challenges of identifying positive selection in the presence of bottlenecks [74], along with uncertainty regarding the portion of the genome affected by adaptive population differences, may also contribute to these findings. Both analyses, however, should motivate new adaptive hypotheses to be tested via detailed population genetic analyses and experimental approaches.
If the rapid introgression of non-African genotypes into African populations documented above is driven by natural selection, then sharp peaks and valleys of admixture along the genome (Figure 4) should contain functional differences between sub-Saharan and cosmopolitan populations. Such differences may have been driven by natural selection after these populations diverged, and hence may be detectable by the Africa-Europe FST outlier scan presented above. Given that the scale of these FST outliers (on the order of 10 kb) is narrower than our admixture peaks and valleys (on the order of 100 kb), population genetic signals of elevated differentiation may be helpful in localizing genes responsible for driving or opposing non-African gene flow into African populations.
We selected eight clear genomic peaks of admixture within the higher recombination regions analyzed for FST. These peaks were delimited by windows containing the local maximum number of admixed genomes, and identified FST outlier regions that either overlapped them or were within 100 kb. Valleys of admixture were more difficult to clearly distinguish from gaps between peaks and minor fluctuations (Figure 4) – three were identified, one of which overlapped several FST outlier regions (Table S19). For peaks of admixture, seven of these eight regions were associated with FST outlier regions (Table S19), exceeding random expectations (permutation P = 0.017). Stronger outlier regions associated with admixture peaks included the genes Bar-H1, Enhancer of split, Neuropeptide Y receptor-like, and sevenless. Further studies will be needed to evaluate the possibility that cosmopolitan alleles at one or more of these loci may now confer a fitness advantage in urban African environments.
Conclusions and Prospects
Here, we have described variation across more than one hundred D. melanogaster genomes, focusing on the species' sub-Saharan ancestral range. We observed clear evidence of cosmopolitan admixture at varying levels in all sub-Saharan populations. While admixture initially appeared to be merely a barrier to studying African variation, inferred patterns of admixture suggested that this process is associated with intriguing biological dynamics. Based on the apparent speed of introgression, the association of admixture with urban environments, and dramatically differing admixture levels across the genome (with peak admixture levels correlated with outliers for Africa-Europe FST), it appears that admixture may be a primarily non-neutral process. Unexpected variance in admixture proportion within populations provides another departure from simple models, and could indicate isolation mechanisms within African populations.
We observed the greatest genetic diversity in a Zambian sample and nearby populations, suggesting a possible geographic origin for the species. Even at a broad genomic scale, however, it appears that genetic diversity does not always reflect demographic expectations. We observed chromosome arm-specific deviations in population diversity ratios, most notably for comparisons involving the European population: genetically differentiated inverted chromosomes strongly influence autosomal diversity in our France sample, potentially due to recent natural selection elevating the frequency of introgressing inversions with African origin. Considering this hypothesis alongside our admixture inferences, it is conceivable that selection has driven gene flow in both directions across the sub-Saharan/cosmopolitan genetic divide, with consequences for genome-wide levels and patterns of diversity. Additional studies are needed to evaluate models of population history, natural selection, and inversion polymorphism that may account for the above patterns.
We have identified numerous genes and processes that may represent targets of positive selection within and between populations. However, further investigations will be needed to confirm targets of selection and their functional significance. Such studies may help reveal the biological basis of this species' adaptation to temperate environments, as well as contrasting environments within Africa, while potentially also providing more general insights into the genetic basis of adaptive evolution.
Although the aims of this publication are primarily descriptive, data such as that presented here may play an important role in resolving some long-standing controversies in population genetics. It's clear that natural selection plays an important role in shaping sequence divergence between Drosophila species and in reducing polymorphism in genomic regions of low recombination. However, the relative importance of natural selection and neutral forces in governing levels and patterns of variation in regions of higher recombination is unresolved. We still do not know if, for example, linked hitchhiking events have an important influence on diversity at most sites in the genome. The relative impact of population history and natural selection on genetic diversity during the out-of-Africa expansion of D. melanogaster is also uncertain. And in regions of low recombination, the relative contributions of hitchhiking and background selection in reducing genetic variation have not been quantified. It is our hope that population genomic data sets like this one will motivate theoretical and simulation studies that advance our fundamental understanding of how evolutionary forces shape genetic variation.
Note added in proof
Consensus sequences with reduced reference bias are now available from http://www.dpgp.org/dpgp2/dpgp2.html
Materials and Methods
Drosophila stocks and DNA preparation
Genomes reported here are derived from the population samples listed in Table S1 and depicted in Figure 1. The collection methods for samples collected in 2004 or later correspond to a published protocol [80]. Information about individual fly stocks is presented in Table S2. Most of the relevant stocks are isofemale lines, each founded from a single wild-caught female. In some cases, intentional inbreeding was conducted by sib-mating for five generations; such lines have an ‘N’ appended to the isofemale line label. Although not a focus of our analysis, we have also released genomic data from a small number of chromosome extraction lines, created using balancer stocks.
Except for the three ZK genomes, DNA for all inbred and isofemale lines was obtained from haploid embryos [30]. Briefly, a female fly from the stock of interest was mated to a male homozygous for the ms(3)K811 allele [81]. This mating produces some eggs which are fertilized but fail to develop because the clastogenic paternal genome. Rarely, such eggs bypass apparent checkpoints and develop as haploid embryos. Eggs with partially developed first instars were visually identified under a microscope. DNA was isolated from haploid embryos and genome-amplified as previously described [30]. For the ZK genomes and chromosome extraction lines, DNA was isolated from 30 adult flies (generally females; mixed sexes in the case of autosomal extraction lines). For all samples, library preparation for sequencing (ligation of paired end adapters, selection of ∼400 bp fragments, and PCR enrichment) was conducted as previously described [30]. In some cases, bar code tags (6 bp) were added to allow multiplexing of two or more genomes in one flow cell lane.
Sequencing, assembly, and data filtering
Sequencing was performed using standard protocols for the Illumina Genome Analyzer IIx. Initial data processing and quality analysis was performed using the standard Illumina pipeline. Sequence reads were deposited in the NIH Short Read Archive as project SRP005599. Alignments to the D. melanogaster reference genome (BDGP release 5) using BWA version 0.59 [31] with default settings and the “-I” flag. Program defaults included a 32 bp seed length; reads could therefore map to the reference only if two or fewer reference differences were present within a seed. Although read lengths varied from 76 bp to 146 bp within this data set, only the first 76 bp of longer reads was used for the assemblies reported here. In order to exclude ambiguously mapping reads, those with a BWA mapping quality score less than 20 were eliminated from the assemblies.
Consensus sequences for each assembly were obtained using the SAMtools (version 0.1.16) pileup module [32]. These diploid consensus sequences generally included a few thousand heterozygous calls, scattered across the genome. Such sites are not expected to represent genuine heterozyosity in these haploid/homozygous samples (with the exception of ZK, in which large-scale heterozygosity was observed, presumbaly due to incomplete inbreeding). All putatively heterozygous sites were masked to ‘N’. Sites within 5 bp of a consensus indel were also masked to ‘N’ – this criterion was found to reduce errors associated with indel alignment; no appreciable benefit was observed if 10 bp was masked instead (data not shown).
Data were only considered for “target” chromosome arms, as defined in Table S1. These are chromosome arms expected to derive from the population sample of interest (as opposed to originating from laboratory balancer stocks), and observed to be free of heterozygous intervals. Chromosome arms were further defined as “focal” (the genomic regions analyzed here, namely the euchromatic portions of X, 2L, 2R, 3L, and 3R) or “non-focal” (the mitochondria and heterochromatin, including chromosomes 4 and Y). The assemblies analyzed here were defined as “release 2” data and are available for download at http://www.dpgp.org/dpgp2/DPGP2.html. Assemblies of mitochondrial and bacterial symbiont genomes are reported and analyzed separately [47].
Estimation of consensus error rate
Although the above assemblies provide nominal quality scores, we performed a separate evaluation of statistical confidence in the accuracy of assemblies. This analysis utilized five haploid embryo, reference strain (y1 cn1 bw1 sp1) genomes resequenced with comparable depth and read characteristics as the non-reference genomes reported here (Table S2). In order to simulate the effects of genetic variation, the maq fakemut program [82] was used to introduce artificial substitutions and indels into the resequenced reference genomes. Substitutions were introduced at rate 0.012/bp, while 1 bp indels were introduced at rate 0.0024/bp. Alignment and consensus sequence generation was then performed as described above.
The artificially mutagenized reference genomes allowed us to examine the tradeoff between minimizing error rates and maximizing genomic coverage. Based on the joint pattern of these quantities for various nominal quality scores (Figure S1), we selected a nominal quality threshold of Q31 as the basis for downstream analyses. The observed consensus sequence error rate for the nominal Q31 cutoff suggested was equivalent to an average Phred score of Q48 (roughly one error per 100 kb).
Detection of identical-by-descent genomic regions
Long tracts of identity-by-descent (IBD) between genomes may result from the sampling of related individuals. Because such relatedness violates the assumptions of many population genetic models, we sought to identify and mask instances of IBD caused by relatedness. Target chromosomes from all possible pairs of genomes were compared to search for long intervals of identity-by-descent (IBD) that may result from close relatedness. Following Langley et al. [28], windows 500 kb in length were moved in 100 kb increments across the genome, and sequence identity was defined as less than 0.0005 pairwise differences per site. A large number of pairwise intervals fit this criterion (Table S3). Some chromosomal intervals, including centromeres and telomeres, had recurrent IBD in between-population comparisons (Table S4). Cross-population IBD occurred at scales up to 4 Mb within these manually delimited “recurrent IBD regions”, and its occurrence between different populations suggests that processes other than close relatedness are responsible. Such intervals were not masked from the data. We identified clear instances of “relatedness IBD” between two genomes when within-population IBD exceeded the scale observed between populations: when more than 5 Mb of summed genome-wide IBD tracts occurred outside recurrent IBD regions, or when tracts greater than 5 Mb overlapped recurrent IBD regions. Only nine pairs of genomes met one or both of these criteria (Table S4), and two of these pairs were expected based on the common origin of isofemale and chromosome extraction lines (Table S2). For these pairs, one of the two genomes was chosen for filtering, and all identified IBD intervals from this pairwise comparison were masked to ‘N’ for most subsequent analyses.
Admixture detection method—overview
Relevant for the inference of non-African admixture is a panel of eight primary core genomes from France (the “FR” sample). D. melanogaster populations from outside sub-Saharan Africa show reduced genetic diversity and are more closely related to each other than to sub-Saharan populations [22], [26]. Hence, whether admixture came from Europe or elsewhere in the diaspora, FR should represent an adequate “reference population” for the source of non-African admixture. However, we lack an African population that is known to be free of admixture. And while a variety of statistical methods exist for the detection of admixture, options for detecting unidirectional admixture using a single reference population are more limited. We therefore developed a new method to detect admixture in this data set.
We constructed a windowed Hidden Markov Model (HMM) machine learning approach based on a given haplotype's average pairwise divergence from the non-African reference population (DFR). The admixed state is based on comparisons of individual FR haplotypes to the remainder of the FR sample. The non-admixed state is based on comparisons of haplotypes from a provisional “African panel” to the FR sample. Here, 22 genomes from the Rwanda “RG” sample are used as the African panel. We allow for the possibility of admixture within the African panel as described below.
Formally, the emissions distribution for the non-admixed state was constructed as follows. For each window, each RG haplotype was evaluated for average pairwise divergence from the FR sample (DRG,FR). Each of these values was rescaled in terms of standard deviations of DRG,FR from the window mean DRG,FR. Standardized values were added to the emissions distribution in bins of 0.1 standard deviations, and these bins were ultimately rescaled to sum to 1. Hence, the emissions distribution reflects the genome-wide pattern of DRG,FR, accounting for local patterns of diversity.
The emissions distribution for the admixed state was constructed similarly. For each window, each FR haplotype was evaluated for average pairwise divergence from the remainder of the FR sample (DFR,FR). However, these DFR,FR values were still rescaled by the window mean and standard deviation of DRG,FR. An alternative version of the method in which the admixed state's emissions distribution was instead rescaled by the local mean and standard deviation of DFR,FR was slightly less accurate when applied to simulated data.
Given these genome-wide emissions distributions, we can examine DRG,FR for each African allele for each window, and obtain its likelihood if we are truly making an “Africa-Europe comparison” with this DRG,FR (non-admixed state) or if we are actually making a “Europe-Europe comparison” (admixed state). These likelihoods form the input for the HMM process, which was performed using an implementation [83] of the forward-backward algorithm. A minimum admixture likelihood of 0.005 was applied to HMM input, in order to reduce the influence of a single unusual window. Admixed intervals were defined as windows with >50% posterior probability for the admixed state. For the purpose of masking admixed genomic intervals for downstream analyses, one window on each side of admixed intervals was added (to account for uncertainty in the precise boundaries of admixture tracts).
Admixture detection method—validation
The admixture detection method was tested using simulated data containing known admixture tracts. Population samples of sequences 10 Mb in length were simulated using MaCS [84], which can approximate coalescent genealogies across long stretches of recombining sequence. Demographic parameters were based on a published model for autosomal loci [13], [23]. The command line used was “./macs04 63 10000000 -s 12345 -i 1 -h 1000 -t 0.0376 -r 0.171 -c 5 86.5 -I 2 27 36 0 -en 0 2 0.183 -en 0.0037281 2 0.000377 -en 0.00381 2 1 -ej 0.00381000001 2 1 -eN 0.0145 0.2”, specifying simulations with present population mutation rate 0.0376 and population recombination rate 0.171, gene conversion parameters based on a weighted average of loci from Yin et al. [85], and historic tree retention parameter h = 1000 [84].
The above simulations generate population samples that may resemble data from sub-Saharan and cosmopolitan populations of D. melanogaster, but they do not involve any admixture. If admixture was specified with the command line, then without modifications to the simulation program, there would not be an output record of admixture tract locations. Instead, extra “non-African” haplotypes were simulated (one for each African haplotype), and these “donor alleles” became the source for admixture tracts which were spliced into the African population's data after MaCS simulation was completed.
The locations and lengths of admixture tracts were determined by a separate simulation process. The forward simulation program developed by Pool and Nielsen [36] accounts for drift, recombination, and migration, recording intervals with migrant history. By using this program to simulate a region symmetric to the African MaCS data, we identified intervals that should contain admixture tracts after g generations of admixture. These intervals were then spliced from the non-African donor alleles into African haplotypes from the MaCS simulated polymorphism data.
The simulated data with admixture was then analyzed using the admixture HMM method described above. In this case, windows of 10 kb were analyzed. Times since the onset of admixture (g) of 100, 1000, and 10000 generations were examined. Migration rates were specified to approximate a total admixture proportion of 10% (hence testing the robustness of the method to this level of admixture in the “African panel”).
As indicated by representative simulation results shown in Figure S8, the admixture detection method was highly accurate for g = 100 and g = 1000, and moderately accurate for g = 10000. Based on preliminary observations from the data, we suspected that much of the admixture in our data set was on the order of g = 100 or less.
Admixture detection method—implementation
The admixture HMM was initially applied to the RG sample alone. Compared with the simulated data, the empirical data showed more overlap between the admixed and non-admixed emissions distributions. This contrast could result from demographic differences between the African population used here (from Rwanda) and the one from which demographic parameter estimates were obtained (from Zimbabwe), and/or an effect of positive selection making Africa-Europe diversity comparisons more locally heterogeneous than expected under neutrality. We responded by expanding the window size used in the empirical data analysis. Windows were based on numbers of non-singleton polymorphic sites among the 22 RG primary core genomes. We chose a window size of 1000 such SNPs, which corresponds to a median window size close to 50 kb. Smaller windows led to noisier likelihoods (results not shown), while larger windows might exclude short admixture tracts without an appreciable gain in accuracy.
Another concern regarding the empirical data was the effect of sequencing depth on pairwise divergence values. After restricting the admixture analysis to genomes with >25X mean depth, we still observed a minor degree of “wavering” in admixture probabilities for genomes with the lowest depth. We therefore applied a simple correction factor to approximate each genome's quality effects on divergence metrics. In theory, we wish to know the effect of depth and other aspects of quality on DFR. In practice, however, genomes differ in DFR in part based on their level of admixture. Instead, DRG (average pairwise divergence from the rest of the Rwanda sample) was used as a proxy. For each chromosome arm, a genome's DRG was compared to the RG population average. Each genome's DFR was then multiplied by the correction factor . Following this correction, no effect of depth on admixture inferences was observed within the primary core data set.
Although simulations suggested that our admixture method is robust to ∼10% admixture in the African panel, we sought to maximize the method's accuracy by applying it iteratively to the RG sample. Identical-by-descent regions (as defined above) were masked during the creation of emissions distributions, but likelihoods were then evaluated for full RG chromosome arms. After one full “round” of the method (emissions, likelihoods, and HMM), admixture tracts were masked from the RG sample. This masked RG sample became the revised African panel for a second round of analysis, this one with a more accurate emissions distribution for the non-admixed state (since it contains more true “Africa-Europe” comparisons, and is presumably less influenced by admixture). Admixture masking for RG was redone based on round 2 admixture intervals, and the re-masked RG data was used to create a third and final set of emissions distributions. The round 3 emissions distributions were used to generate final admixture calls not only for the RG sample, but also for the other African genomes in the primary core data set.
The use of RG as an “African panel” when examining admixture in other African populations is not without concern. Fortunately, in addition to being the largest African sample, RG also occupies a genetically intermediate position within Africa (see results section), which reduces the potential impact of genetic structure on the accuracy of admixture inferences for non-RG genomes. It also appears that aside from the effects of admixture, no other African sample has a much closer relationship to FR than RG does (see results section), thus mitigating a potential source of bias.
Analysis of admixture detection results
Standard linear regression was used to investigate the possible relationship between cosmopolitan admixture proportion (for a population sample) and the human population size of the collection locality (city, town, or village population size). Census-based population estimates were obtained from online sources for 15 of 20 population samples. For the remainder, satellite-based estimates were obtained from fallingrain.com (Table S1). While a set of uniform and perfectly accurate population figures is not available for these locations, the estimates used here may still allow a significant effect of human population size on cosmopolitan admixture proportion to be detected.
The centiMorgan length of each admixture interval was calculated based on recombination rates inferred from smoothed genetic map data [28]. The extra buffer windows added to each side of conservative admixture tract delimitations described above were not included in these length estimates. CentiMorgan tract lengths were then used with a method [36] that estimates three parameters of a migration rate change model: the current migration rate, the previous migration rate, and the time of migration rate change. A minimum detectable tract length of 0.5 cM was chosen, corresponding to roughly 200 kb or 4 windows on average. Forward simulations [36] including recombination, migration, and drift were performed under the estimated demographic model. Simulated data were compared to empirical data, to test how often simulated variance in cosmopolitan admixture proportion exceeded that observed in the RG sample.
Genetic diversity and structure of populations
Regions of lower recombination proximal to centromeres and telomeres were excluded from most analyses, except where indicated below. Recombination rates were taken from mapping-based estimates [28], and the threshold between “low” and “high” recombination rates was defined as 2×10−8 cross-overs per bp per generation. In most cases, a single transition point was apparent where a chromosome arm transitioned from low to high recombination, moving away from a centromere or telomere. A few narrow “valleys” of recombination rate estimates slightly below this threshold within broader high recombination regions, along with one peak of recombination rate slightly above this threshold close to the 3L centromere, were ignored in the definition of centromere-proximal and telomere-proximal boundaries. “Mid-chromosomal intervals” reflecting the higher recombination intervals used in this analysis for each chromosome arm were: X:2,222,391–20,054,556, 2L:464,654–15,063839, 2R:9,551,429–20,635,011, 3L:1,979,673–12,286,842, 3R:12,949,344–25,978,664.
Principal components analysis (PCA) was conducted using the method of Patterson et al. [43]. Mid-chromosomal data from all primary core genomes were included. The analysis was run twice, on data sets with and without admixture filtering. Applying additional filters (excluding sites with >5% missing data or <2.5% minor allele frequency) had little effect on results.
Nucleotide diversity (π) was initially calculated in 100 kb windows, and weighted values for each population sample (based on the number of sites in each window with data from at least two genomes) were then averaged to obtain a population's mean absolute π for each chromosome arm. Relative π was calculated by obtaining the ratio of window π from a given population versus that for the RG population (the largest African sample), and window ratios were weighted by the number of sites with data from two or more RG genomes. Relative π values should therefore be robust to cases where a population has large blocks of masked data in a genomic region with especially high or low diversity (since π in each window is standardized by that observed for the RG sample), which could bias estimates of absolute π. Genome-wide relative π was calculated as the unweighted average value of the five major chromosome arms. Three samples (CK, RC, SP) had only one primary core genome, but one or more secondary core genomes. Relative π for these samples was calculated based on comparisons between primary and secondary core genomes, both for the target sample and for RG (which also contains primary and secondary core genomes). A similar re-estimation of relative π for the CO sample yielded genome-wide relative π of 0.914 from primary-secondary comparisons, versus 0.927 from primary core genomes only.
Dxy, the average rate of nucleotide differences between populations, was calculated for a subset of populations with high levels of genomic coverage in the admixture-filtered data (CO, ED, FR, GA, GU, KR, NG, RG, TZ, UG, ZI, ZS). FST was calculated using the method of Hudson et al. [58], with equal population weightings regardless of their sample sizes. Arm-wide and genome-wide estimates of both statistics were calculated as described above for relative π.
Using the above summary statistics, we calculated the ratio of a population's DZI (genetic distance from the four Zambia ZI genomes) to πZI. Here, the intention was to test which populations contained unique genetic diversity not observed in the maximally diverse ZI population, leading to ratios greater than one. The significance of ratios greater than one was assessed via a bootstrapping approach. Windows 100 kb in length were sampled with replacement until 667 were drawn, to match the number present in non-centromeric, non-telomeric regions of the empirical data. One million such replicates were conducted for each population, and the proportion of replicates with a ratio less than one became the bootstrapping P value. The use of windows much larger than the scale of linkage disequilibrium implies a conservative test.
For each population's genome-wide relative π (Figure 6), and for the DZI to πZI ratio (Table 2; described), we applied a correction factor to reduce the predicted influence of sequencing depth on these quantities. From a linear regression of primary core genomes' sequencing depth versus DZI (Figure 2), the slope and y intercept of this relationship were obtained. Based on population mean sequencing depth, a population's predicted DZI was compared to the predicted DZI of the reference population (RG for π, ZI for the ratio analysis). Observed summary statistic were multiplied by the ratio of these predicted values to obtain a corrected estimate. For both statistics, this adjustment led to changes of ∼1% or less.
Linkage disequilibrium from empirical and simulated data
In addition to the standard correlation coefficient (r2) of linkage disequilibrium (LD), we also examined directional LD via the rω statistic [70], [71]. Here, LD is defined as positive if minor alleles preferentially occur on the same haplotype, and otherwise LD is negative. Empirical LD patterns were compared to data simulated under neutral evolution and equilibrium demography using ms [86]. In these simulations, the population mutation rate was taken from observed π. The population recombination rate was then inferred from the ratio of empirical estimates of recombination rates (the average rate from Langley et al. [28] for the analyzed X-linked and autosomal regions, simulated separately) and mutation rate [87]. Estimates for the rate of gene conversion relative to crossover events (5x) and the average gene conversion tract length (86.5 bp) were taken from a weighted average of the locus-specific estimates obtained by Yin et al. [85].
Genomic scans for loci with unusual allele frequencies
The Λmax statistic of Sweepfinder [75] uses allele frequencies to evaluate the relative likelihood of a selective sweep versus neutral evolution. To add information regard diversity reductions, we implemented the approach of Pavlidis et al. [76] to include a fraction of the invariant sites. One invariant site was added to the input for every 10 invariant sites that had <50% missing data. Likelihoods were evaluated for 1000 positions from each window. The folded allele frequency spectrum from short intron sites (see below) was used for background allele frequencies, assumed by the method to represent neutral evolution.
Local outliers for Λmax and FST were examined in overlapping windows of 100 RG non-singleton SNPs (roughly 5 kb on average). For FST, overlapping windows were offset by increments of 20 RG non-singleton SNPs, in order to identify outlier loci that could result from adaptive population differentiation. Outlier windows were defined by the upper 2.5% (FST) or 5% (Λmax) quantile for each chromosome arm. The lower threshold for FST avoids an excessive number of outliers due to the greater number of (overlapping) windows, compared to the non-overlapping windows for Λmax. Outliers with up to two non-overlapping non-outlier windows between them were considered as part of the same “outlier region”, since they might reflect a single evolutionary signal. For FST, the center of an outlier region was defined as the midpoint of its most extreme window. The nearest gene to an outlier region was calculated based on the closest exon (protein-coding or untranslated) to the above location, based on D. melanogaster genome release 5.43 coordinates obtained from Flybase.
Two FST outlier analyses were conducted. One, with the aim of identifying loci that may have contributed to the adaptive difference between African and cosmopolitan populations, focused on FST between the FR and RG population samples. The other scan was intended to search for potential adaptive differences among African populations. The nine population samples with a mean post-filtering sample size above 3.75 were included (CO, ED, GA, GU, NG, RG, UG, ZI, ZS). The mean FST from all pairwise population comparisons was evaluated for each window, and outlier regions for this overall FST were obtained. Each population was also analyzed separately, in terms of the mean FST from eight pairwise population comparisons. Here, outliers were analyzed separately for each African population, but the lists of population-specific outliers were also combined for more statistically powerful enrichment tests.
The enrichment of gene ontology (GO) categories among sets of outliers was evaluated. For each GO category, the number of unique genes that were the closest to an outlier region center (see above) was noted. A P value was then calculated, representing the probability of observing as many (or more) outlier genes from that category under the null hypothesis of a random distribution of outlier region centers across all windows. Calculating null probabilities based on windows, rather than treating each gene identically, accounts for the fact that genes vary greatly in length, and hence in the number of windows that they are associated with. P values were obtained from a permutation approach in which all outlier region center windows were randomly reassigned 10,000 times (results not shown).
Supporting Information
Zdroje
1. AdamsMD, CelnikerSE, HoltRA, EvansCA, GocayneJD, et al. (2000) The genome sequence of Drosophila melanogaster. Science 287: 2185–2195.
2. RoyS, ErnstJ, KharchenkoPV, KheradpourP, NegreN, et al. (2010) Identification of functional elements and regulatory circuits by Drosophila modENCODE. Science 330: 1787–1797.
3. DobzhanskyT, SturtevantAH (1938) Inversions in the Chromosomes of Drosophila pseudoobscura. Genetics 23: 28–64.
4. LewontinRC, HubbyJL (1966) A molecular approach to the study of genic heterozygosity in natural populations. II. Amount of variation and degree of heterozygosity in natural populations of Drosophila pseudoobscura. Genetics 54: 595–609.
5. SinghRS, HickeyDA, DavidJ (1982) Genetic differentiation between geographically distant populations of Drosophila melanogaster. Genetics 101: 235–256.
6. MettlerLE, VoelkerRA, MukaiT (1977) Inversion clines in populations of Drosophila melanogaster. Genetics 87: 169–176.
7. HudsonRR, KreitmanM, Aguadé (1987) A test of neutral molecular evolution based on nucleotide data. Genetics 116: 153–159.
8. McDonaldJH, KreitmanM (1991) Adaptive protein evolution at the Adh locus in Drosophila. Nature 351: 652–654.
9. BegunDJ, AquadroCF (1992) Levels of naturally occurring DNA polymorphism correlate with recombination rates in D. melanogaster. Nature 356: 519–520.
10. Maynard SmithJ, HaighJ (1974) The hitch-hiking effect of a favourable gene. Genet Res 23: 23–35.
11. CharlesworthB, MorganMT, CharlesworthD (1993) The effect of deleterious mutations on neutral molecular variation. Genetics 134: 1289–1303.
12. KauerMO, DieringerD, SchlöttererC (2003) A microsatellite variability screen for positive selection associated with the “out of Africa” habitat expansion of Drosophila melanogaster.
13. HutterS, LiH, BeisswangerS, De LorenzoD, StephanW (2007) Distinctly different sex ratios in African and European populations of Drosophila melanogaster inferred from chromosomewide single nucleotide polymorphism data. Genetics 177: 469–480.
14. SmithNGC, Eyre-WalkerA (2002) Adaptive protein evolution in Drosophila. Nature 415: 1022–1024.
15. AndolfattoP (2005) Adaptive evolution of non-coding DNA in Drosophila. Nature 437: 1149–1152.
16. Lachaise D, Cariou ML, David JR, Lemeunier F, Tsacas L, et al.. (1988) Historical biogeography of the Drosophila melanogaster species subgroup. In: Hecht MK, Wallace B, Prance GT, eds. Evolutionary biology. New York: Plenum. pp. 159–225.
17. BegunDJ, AquadroCF (1993) African and North American populations of Drosophila melanogaster are very different at the DNA level. Nature 365: 548–550.
18. PoolJE, AquadroCF (2006) History and structure of sub-Saharan populations of Drosophila melanogaster. Genetics 174: 915–929.
19. LachaiseD, SilvainJ-F (2004) How two Afrotropical endemics made two cosmopolitan commensals: the Drosophila melanogaster – D. simulans paleogeographic riddle. Genetica 120: 17–39.
20. VeuilleM, BaudryE, CobbM, DeromeN, GravotE (2004) Historicity and the population genetics of Drosophila melanogaster and D. simulans. Genetica 120: 61–70.
21. HaddrillPR, ThorntonKR, CharlesworthB, AndolfattoP (2005) Multilocus patterns of nucleotide variability and the demographic and selection history of Drosophila melanogaster populations. Genome Res 15: 790–799.
22. BaudryE, ViginierB, VeuilleM (2004) Non-African populations of Drosophila melanogaster have a unique origin. Mol Biol Evol 21: 1482–1491.
23. LiH, StephanW (2006) Inferring the demographic history and rate of adaptive substitution in Drosophila. PLoS Genet 2: e166 doi:10.1371/journal.pgen.0020166.
24. ThorntonKR, AndolfattoP (2006) Approximate Bayesian inference reveals evidence for a recent, severe bottleneck in a Netherlands population of Drosophila melanogaster. Genetics 172: 1607–1619.
25. Lintner JA (1882) First annual report on the injurious and other insects of the State of New York. Albany, New York: Weed, Parsons, and Co.
26. CaracristiG, SchlöttererC (2003) Genetic differentiation between American and European Drosophila melanogaster populations could be attributed to admixture of African alleles. Mol Biol Evol 20: 792–799.
27. BegunDJ, HollowayAK, StevensK, HillierLW, PohYP, et al. (2007) Population genomics: whole-genome analysis of polymorphism and divergence in Drosophila simulans. PLoS Biol 5: e310 doi:10.1371/journal.pbio.0050310.
28. LangleyCH, StevensK, CardenoC, LeeYCG, SchriderDR, et al. (2012) Genomic variation in natural populations of Drosophila melanogaster. Genetics In Press.
29. MackayTFC, RichardsS, StoneEA, BarbadillaA, AyrolesJF, et al. (2012) The Drosophila melanogaster genetic reference panel. Nature 482: 173–178.
30. LangleyCH, CrepeauM, CardenoC, Corbett-DetigR, StevensK (2011) Circumventing heterozygosity: sequencing the amplified genome of a single haploid Drosophila melanogaster embryo. Genetics 188: 239–246.
31. LiH, DurbinR (2009) Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25: 2078–2079.
32. LiH, HandsakerB, WysokerA, FennellT, RuanJ, et al. (2009) The Sequence Alignment/Map format and SAMtools. Bioinformatics 25: 2078–2079.
33. CapyP, VeuilleM, PailletteM, JallonJ-M, VouidibioJ, et al. (2000) Sexual isolation of genetically differentiated sympatric populations of Drosophila melanogaster in Brazzaville, Congo: the first step towards speciation? Heredity 84: 468–475.
34. KauerM, DieringerD, SchlöttererC (2003) Nonneutral admixture of immigrant genotypes in African Drosophila melanogaster populations from Zimbabwe. Mol Biol Evol 20: 1329–1337.
35. VouidibioJ, CapyP, DefayeD, PlaE, SandrinE, et al. (1989) Short-range genetic structure of Drosophila melanogaster populations in an Afrotropical urban area and its significance. Proc Natl Acad Sci USA 86: 8442–8446.
36. PoolJE, NielsenR (2009) Inference of historical changes in migration rate from the lengths of migrant tracts. Genetics 181: 711–719.
37. CataniaF, KauerMO, DabornPJ, YenJL, Ffrench-ConstantRH, et al. (2004) A world-wide survey of an Accord insertion and its association with DDT resistance in Drosophila melanogaster. Mol Ecol 13: 2491–2504.
38. WuC-I, HollocherH, BegunDJ, AquadroCF, XuY, et al. (1995) Sexual isolation in Drosophila melanogaster: a possible case of incipient speciation. Proc Natl Acad Sci USA 92: 2519–2523.
39. HollocherH, TingC-T, PollackF, WuC-I (1997) Incipient speciation by sexual isolation in Drosophila melanogaster: variation in mating preference and correlation between the sexes. Evolution 51: 1175–1181.
40. CharlesworthB, CoyneJA, BartonNH (1987) The relative rates of evolution of sex chromosomes and autosomes. Am Nat 130: 113–146.
41. AulardS, DavidJR, LemeunierF (2002) Chromosomal inversion polymorphism in Afrotropical populations of Drosophila melanogaster. Genet Res 79: 49–63.
42. LucchesiJC, SuzukiDT (1968) The interchromosomal control of recombination. Ann Rev Genet 2: 53–86.
43. PattersonN, PriceAL, ReichD (2006) Population structure and eigenanalysis. PLoS Genet 2: e190 doi:10.1371/journal.pgen.0020190.
44. SacktonTB, KulathinalRJ, BergmanCM, QuinlanAR, DopmanEB, et al. (2009) Population genomic inferences from sparse high-throughput sequencing of two populations of Drosophila melanogaster. Genome Biol Evol 1: 449–465.
45. van HerrewegeJ, DavidJR (1997) Starvation and desiccation tolerances in Drosophila: comparison of species from different climatic origins. Ecoscience 4: 151–157.
46. StanleySM, ParsonsPA, SpenceGE, WeberL (1980) Resistance of species of the Drosophila melanogaster subgroup to environmental extremes. Aust J Zool 28: 413–421.
47. Richardson MF, Weinert LM, Welch JJ, Linheiro RS, Magwire MM, et al.. (2012) Population genomics of the Wolbachia endosymbiont in Drosophila melanogaster. (Joint Submission)
48. Corbett-Detig RB, Hartl DL (2012) Population genomics of inversion polymorphisms in Drosophila melanogaster. (Joint Submission)
49. GuerreroRF, RoussetF, KirkpatrickM (2012) Coalescent patterns for chromosomal inversions in divergent populations. Phil Trans R Soc B 367: 430–438.
50. HassonE, EanesWF (1996) Contrasting histories of three gene regions associated with In(3L)Payne of Drosophila melanogaster. Genetics 144: 1565–1575.
51. AndolfattoP, PrzeworskiM (2001) Regions of lower crossing over harbor more rare variants in African populations of Drosophila melanogaster. Genetics 158: 657–665.
52. GreenbergR, CrowJF (1960) A comparison of the effect of lethal and detrimental chromosomes from Drosophila populations. Genetics 8: 1153–1168.
53. DobzhanskyT (1954) Evolution as a creative process. Proceedings of the 9th International Congress on Genetics, Bellagio, Italy 1: 435–449.
54. OhtaT (1971) Associative overdominance caused by linked detrimental mutations. Genet Res 18: 277–286.
55. KirkpatrickM, BartonN (2006) Chromosome inversions, local adaptation and speciation. Genetics 173: 419–434.
56. BierneN, TsitroneA, DavidP (2000) An inbreeding model of associative overdominance during a population bottleneck. Genetics 155: 1981–1990.
57. PoolJE, NielsenR (2008) The impact of founder events on chromosomal variability in multiply mating species. Mol Biol Evol 25: 1728–1736.
58. HudsonRR, SlatkinM, MaddisonWP (1992) Estimation of levels of gene flow from DNA sequence data. Genetics 132: 583–589.
59. HalliganDL, KeightleyPD (2006) Ubiquitous selective constraints in the Drosophila genome revealed by a genome-wide interspecies comparison. Genome Res 16: 875–884.
60. ParschJ, NovozhilovS, Saminadin-PeterSS, WongKM, AndolfattoP (2010) On the utility of short intron sequences as a reference for the detection of positive and negative selectioni in Drosophila. Mol Biol Evol 27: 1226–1234.
61. SellaG, PetrovDA, PrzeworskiM, AndolfattoP (2009) Pervasive natural selection in the Drosophila genome? PLoS Genet 5: e1000495 doi:10.1371/journal.pgen.1000495.
62. JensenJD, ThorntonKR, AndolfattoP (2008) Approximate Bayesian estimator suggests strong, recurrent selective sweeps in Drosophila. PLoS Genet 4: e1000198 doi:10.1371/journal.pgen.1000198.
63. PoolJE, NielsenR (2007) Population size changes reshape genomic patterns of diversity. Evolution 61: 3001–3006.
64. BravermanJM, HudsonRR, KaplanNL, LangleyCH, StephanW (1995) The hitchhiking effect on the site frequency spectrum of DNA polymorphisms. Genetics 140: 783–796.
65. PenningsPS, HermissonJ (2006) Soft sweeps III: the signature of positive selection from recurrent mutation. PLoS Genet 2: e186 doi:10.1371/journal.pgen.0020186.
66. CharlesworthD, CharlesworthB, MorganMT (1995) The pattern of neutral molecular variation under the background selection model. Genetics 141: 1619–1632.
67. ZengK, CharlesworthB (2011) The joint effects of background selection and genetic recombination on local gene genealogies. Genetics 189: 251–266.
68. OmettoL, GlinkaS, De LorenzoD, StephanW (2005) Inferring the effects of demography and selection on Drosophila melanogaster populations from a chromosome-wide scan of DNA variation. Mol Biol Evol 22: 2119–2130.
69. ShapiroJA, HuangW, ZhangC, HubiszMJ, LuJ, et al. (2007) Adaptive genic evolution in the Drosophila genomes. Proc Natl Acad Sci USA 104: 2271–2276.
70. LangleyCH, CrowJF (1974) The direction of linkage disequilibrium. Genetics 78: 937–941.
71. LangleyCH, TobariYN, KojimaK-I (1974) Linkage disequilibrium in natural populations of Drosophila melanogaster. Genetics 78: 921–936.
72. StephanW, SongYS, LangleyCH (2006) The hitchhiking effect on linkage disequilibrium between linked neutral loci. Genetics 172: 2647–2663.
73. Chan AH, Jenkins P, Song YS (2012) Genome-wide fine-scale recombination rate variation in Drosophila melanogaster. (Joint Submission)
74. JensenJD, KimY, Bauer DuMontV, AquadroCF, BustamanteCD (2005) Distinguishing between selective sweeps and demography using DNA polymorphism data. Genetics 170: 1401–1410.
75. NielsenR, WilliamsonS, KimY, HubiszMJ, ClarkAG, et al. (2005) Genomic scans for selective sweeps using SNP data. Genome Res 15: 1566–1575.
76. PavlidisP, JensenJD, StephanW (2010) Searching for footprints of positive selection in whole-genome SNP data from nonequilibrium populations. Genetics 185: 907–922.
77. AguadéM (2009) Nucleotide and copy-number polymorphism at the odorant receptor genes Or22a and Or22b in Drosophila melanogaster. Mol Biol Evol 26: 61–70.
78. AminetzachYT, MacphersonJM, PetrovDA (2005) Pesticide resistance via transposition-mediated adaptive gene truncation in Drosophila. Science 309: 764–767.
79. MagwireMM, BayerF, WebsterCL, CaoC, JigginsFM (2011) Successive increases in the resistance of Drosophila to viral infection through a transposon insertion followed by a duplication. PLoS Genet 7: e1002337 doi:10.1371/journal.pgen.1002337.
80. PoolJE (2009) Notes regarding the collection of African Drosophila melanogaster. Dros Inf Serv 92: 130–134.
81. FuyamaY (1984) Gynogenesis in Drosophila melanogaster. Jpn J Genet 59: 91–96.
82. LiH, RuanJ, DurbinR (2008) Mapping short DNA sequencing reads and calling variants using mapping quality scores. Genome Res 18: 1851–1858.
83. EmersonJJ, Cardoso-MoreiraM, BorevitzJO, LongM (2008) Natural selection shapes genome-wide patterns of copy-number polymorphism in Drosophila melanogaster. Science 320: 1629–1631.
84. ChenGK, MarjoramP, WallJD (2009) Fast and flexible simulation of DNA sequence data. Genome Res 19: 136–142.
85. YinJ, JordanMI, SongYS (2009) Joint estimation of gene conversion rates and mean conversion tract lengths from population SNP data. Bioinformatics 25: i231–i239.
86. HudsonRR (2002) Generating samples under a Wright-Fisher neutral model. Bioinformatics 18: 337–338.
87. KeightleyPD, TrivediU, ThomsonM, OliverF, KumarS, et al. (2009) Analysis of the genome sequences of three Drosophila melanogaster spontaneous mutation accumulation lines. Genome Res 19: 1195–1201.
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2012 Číslo 12
- Mateřský haplotyp KIR ovlivňuje porodnost živých dětí po transferu dvou embryí v rámci fertilizace in vitro u pacientek s opakujícími se samovolnými potraty nebo poruchami implantace
- Intrauterinní inseminace a její úspěšnost
- Akutní intermitentní porfyrie
- Srdeční frekvence embrya může být faktorem užitečným v předpovídání výsledku IVF
- Šanci na úspěšný průběh těhotenství snižují nevhodné hladiny progesteronu vznikající při umělém oplodnění
Nejčtenější v tomto čísle
- Population Genomics of Sub-Saharan : African Diversity and Non-African Admixture
- Excessive Astrocyte-Derived Neurotrophin-3 Contributes to the Abnormal Neuronal Dendritic Development in a Mouse Model of Fragile X Syndrome
- Pre-Disposition and Epigenetics Govern Variation in Bacterial Survival upon Stress
- Insertion/Deletion Polymorphisms in the Promoter Are a Risk Factor for Bladder Exstrophy Epispadias Complex